|
||||||||
|
||||||||

|
Введение в базы данныхАлексей Федоров, Наталия Елманова Основные концепции реляционных баз данных
Этой статьей мы начинаем новый цикл, посвященный базам данных, современным технологиям доступа к данным и их обработки. На протяжении данного цикла мы планируем рассмотреть наиболее популярные настольные и серверные системы управления базами данных (СУБД), механизмы доступа к данным (OLD DB, ADO, BDE и др.) и утилиты для работы с базами данных (средства администрирования, генераторы отчетов, средства графического представления данных). Кроме того, мы планируем уделить внимание методам публикации данных в Internet, а также таким популярным способам обработки и хранения данных, как OLAP (On-Line Analytical Processing), и созданию хранилищ данных (Data Warehousing). В данной статье мы рассмотрим основные понятия и принципы, лежащие в основе систем управления базами данных. Мы обсудим реляционную модель данных, понятие ссылочной целостности и принципы нормализации данных, а также средства проектирования данных. Затем мы расскажем, какими бывают СУБД, какие объекты могут содержаться в базах данных и каким образом осуществляются запросы к этим объектам. Основные концепции реляционных баз данныхНачнем с основных понятий СУБД и краткого введения в теорию реляционных баз данных - наиболее популярного сейчас способа хранения данных.
Реляционная модель данныхРеляционная модель данных была предложена Е.Ф.Коддом (Dr. E.F.Codd), известным исследователем в области баз данных, в 1969 году, когда он был сотрудником фирмы IBM. Впервые основные концепции этой модели были опубликованы в 1970 г. , CACM, 1970, 13 N 6). Реляционная база данных представляет собой хранилище данных, содержащее набор двухмерных таблиц. Набор средств для управления подобным хранилищем называется реляционной системой управления базами данных (РСУБД). РСУБД может содержать утилиты, приложения, сервисы, библиотеки, средства создания приложений и другие компоненты. Любая таблица реляционной базы данных состоит из строк (называемых также записями) и столбцов (называемых также полями). В данном цикле мы будем использовать обе пары терминов. Строки таблицы содержат сведения о представленных в ней фактах (или документах, или людях, одним словом, - об однотипных объектах). На пересечении столбца и строки находятся конкретные значения содержащихся в таблице данных. Данные в таблицах удовлетворяют следующим принципам:
Несмотря на то что строки таблиц считаются неупорядоченными, любая система управления базами данных позволяет сортировать строки и колонки в выборках из нее нужным пользователю способом. Поскольку последовательность колонок в таблице несущественна, обращение к ним производится по имени, и эти имена для данной таблицы уникальны (но не обязаны быть уникальными для всей базы данных). Итак, теперь мы знаем, что реляционные базы данных состоят из таблиц. Для иллюстрации некоторых теоретических положений и для создания примеров нам необходимо выбрать какую-нибудь базу данных. Чтобы не <изобретать колесо>, мы воспользуемся базой данных NorthWind, входящей в комплект поставки Microsoft SQL Server и Microsoft Access. Теперь давайте рассмотрим связи между таблицами.
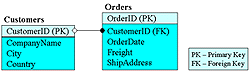
Ключи и связиДавайте взглянем на фрагмент таблицы Customers (клиенты) из базы данных NorthWind (мы удалили из нее поля, несущественные для иллюстрации связей между таблицами). Customers (клиенты)
Поскольку строки в таблице неупорядочены, нам нужна колонка (или набор из нескольких колонок) для уникальной идентификации каждой строки. Такая колонка (или набор колонок) называется первичным ключом (primary key). Первичный ключ любой таблицы обязан содержать уникальные непустые значения для каждой строки. Если первичный ключ состоит из более чем одной колонки, он называется составным первичным ключом (composite primary key). Типичная база данных обычно состоит из нескольких связанных таблиц. Фрагмент таблицы Orders (заказы). Orders (заказы)
Поле CustomerID этой таблицы содержит идентификатор клиента, разместившего данный заказ. Если нам нужно узнать, как называется компания, разместившая заказ, мы должны поискать это же значение идентификатора клиента в поле CustomerID таблицы Customers и в найденной строке прочесть значение поля CompanyName. Иными словами, нам нужно связать две таблицы, Customers и Orders, по полю CustomerID. Колонка, указывающая на запись в другой таблице, связанную с данной записью, называется внешним ключом (foreign key). Как видим, в случае таблицы Orders внешним ключом является колонка CustomerID (Рис. 1).
Рис.1. Первичные и внешние ключи в таблицах Customers и Orders Иными словами, внешний ключ - это колонка или набор колонок, чьи значения совпадают с имеющимися значениями первичного ключа другой таблицы. Подобное взаимоотношение между таблицами называется связью (relationship). Связь между двумя таблицами устанавливается путем присваивания значений внешнего ключа одной таблицы значениям первичного ключа другой. Если каждый клиент в таблице Customers может разместить только один заказ, говорят, что эти две таблицы связаны соотношением один-к-одному (one-to-one relationship). Если же каждый клиент в таблице Customers может разместить ноль, один или много заказов, говорят, что эти две таблицы связаны соотношением один-ко-многим (one-to-many relationship) или соотношением master-detail. Подобные соотношения между таблицами используются наиболее часто. В этом случае таблица, содержащая внешний ключ, называется detail-таблицей, а таблица, содержащая первичный ключ, определяющий возможные значения внешнего ключа, называется master-таблицей. Группа связанных таблиц называется схемой базы данных (database schema). Информация о таблицах, их колонках (имена, тип данных, длина поля), первичных и внешних ключах, а также иных объектах базы данных, называется метаданными (metadata). Любые манипуляции с данными в базах данных, такие как выбор, вставка, удаление, обновление данных, изменение или выбор метаданных, называются запросом к базе данных (query). Обычно запросы формулируются на каком-либо языке, который может быть как стандартным для разных СУБД, так и зависящим от конкретной СУБД.
Ссылочная целостностьВыше мы уже говорили о том, что первичный ключ любой таблицы должен содержать уникальные непустые значения для данной таблицы. Это утверждение является одним из правил ссылочной целостности (referential integrity). Некоторые (но далеко не все) СУБД могут контролировать уникальность первичных ключей. Если СУБД контролирует уникальность первичных ключей, то при попытке присвоить первичному ключу значение, уже имеющееся в другой записи, СУБД сгенерирует диагностическое сообщение, обычно содержащее словосочетание primary key violation. Это сообщение в дальнейшем может быть передано в приложение, с помощью которого конечный пользователь манипулирует данными. Если две таблицы связаны соотношением master-detail, внешний ключ detail-таблицы должен содержать только те значения, которые уже имеются среди значений первичного ключа master-таблицы. Если корректность значений внешних ключей не контролируется СУБД, можно говорить о нарушении ссылочной целостности. В этом случае, если мы удалим из таблицы Customers запись, имеющую хотя бы одну связанную с ней detail-запись в таблице Orders, это приведет к тому, что в таблице Orders окажутся записи о заказах, размещенных неизвестно кем. Если же СУБД контролирует корректность значений внешних ключей, то при попытке присвоить внешнему ключу значение, отсутствующее среди значений первичных ключей master-таблицы, либо при удалении или модификации записей master-таблицы, приводящих к нарушению ссылочной целостности, СУБД сгенерирует диагностическое сообщение, обычно содержащее словосочетание foreign key violation, которое в дальнейшем может быть передано в пользовательское приложение. Большинство современных СУБД, например Microsoft Access 97, Microsoft Access 2000 и Microsoft SQL Server 7.0, способны контролировать соблюдение правил ссылочной целостности, если таковые описаны в базе данных. Для этой цели подобные СУБД используют различные объекты баз данных (мы обсудим их чуть позже). В этом случае все попытки нарушить правила ссылочной целостности будут подавляться с одновременной генерацией диагностических сообщений или исключений (database exceptions).
Введение в нормализацию данныхПроцесс проектирования данных представляет собой определение метаданных в соответствии с задачами информационной системы, в которой будет использоваться будущая база данных. Подробности о том, как производить анализ предметной области, создавать диаграммы <сущность-связь> (ERD - entity-relationship diagrams) и модели данных, выходят за рамки данного цикла. Интересующиеся этими вопросами могут обратиться, например, к книге К.Дж.Дейта <Введение в системы баз данных> ( <Диалектика>, Киев, 1998). В данной статье мы обсудим лишь один из основных принципов проектирования данных - принцип нормализации. Нормализация представляет собой процесс реорганизации данных путем ликвидации повторяющихся групп и иных противоречий в хранении данных с целью приведения таблиц к виду, позволяющему осуществлять непротиворечивое и корректное редактирование данных. Теория нормализации основана на концепции нормальных форм. Говорят, что таблица находится в данной нормальной форме, если она удовлетворяет определенному набору требований. Теоретически существует пять нормальных форм, но на практике обычно используются только первые три. Более того, первые две нормальные формы являются по существу промежуточными шагами для приведения базы данных к третьей нормальной форме.
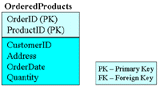
Первая нормальная формаПроиллюстрируем процесс нормализации на примере, использующем данные из базы NorthWind. Предположим, что мы регистрируем все заказанные продукты в следующей таблице.
Структура этой таблицы имеет вид (рис. 2).
Рис.2. Структура ненормализованной таблицы OrderedProducts Чтобы таблица соответствовала первой нормальной форме, все значения ее полей должны быть атомарными, и все записи - уникальными. Поэтому любая реляционная таблица, в том числе и таблица OrderedProducts, по определению, уже находится в первой нормальной форме. Тем не менее эта таблица содержит избыточные данные, например, одни и те же сведения о клиенте повторяются в записи о каждом заказанном продукте. Результатом избыточности данных являются аномалии модификации данных- проблемы, возникающие при добавлении, изменении или удалении записей. Например, при редактировании данных в таблице OrderedProducts могут возникнуть следующие проблемы:
Некоторые из этих проблем могут быть решены путем приведения базы данных ко второй нормальной форме.
Вторая нормальная формаГоворят, что реляционная таблица находится во второй нормальной форме, если она находится в первой нормальной форме и ее неключевые поля полностью зависят от всего первичного ключа. Таблица OrderedProducts находится в первой, но не во второй нормальной форме, так как поля CustomerID, Address и OrderDate зависят только от поля OrderID, являющегося частью составного первичного ключа (OrderID, ProductID). Чтобы перейти от первой нормальной формы ко второй, нужно выполнить следующие шаги:
Например, для приведения таблицы OrderedProducts ко второй нормальной форме, нужно переместить поля CustomerID, Address и OrderDate в новую таблицу (назовем ее OrdersInfo), при этом поле OrderID станет первичным ключом новой таблицы (рис. 3).
Рис.3. Приведение таблицы OrderedProducts ко второй нормальной форме В результате новые таблицы приобретут такой вид. OrdersInfo
OrderDetails
Однако таблицы, находящиеся во второй, но не в третьей нормальной форме, по-прежнему содержат аномалии модификации данных. Вот каковы они, например, для таблицы OrdersInfo:
Устранить эти аномалии можно путем перехода к третьей нормальной форме.
Третья нормальная формаГоворят, что реляционная таблица находится в третьей нормальной форме, если она находится во второй нормальной форме и все ее неключевые поля зависят только от первичного ключа. Таблица OrderDetails уже находится в третьей нормальной форме. Неключевое поле Quantity полностью зависит от составного первичного ключа (OrderID, ProductID). Однако таблица OrdersInfo в третьей нормальной форме не находится, так как содержит зависимость между неключевыми полями (она называется транзитивной зависимостью - transitive dependency) - поле Address зависит от поля CustomerID. Чтобы перейти от второй нормальной формы к третьей, нужно выполнить следующие шаги:
Для приведения таблицы OrdersInfo к третьей нормальной форме создадим новую таблицу Customers и переместим в нее поля CustomerID и Address. Customers
Поле Address из исходной таблицы удалим, а поле CustomerID оставим - теперь это внешний ключ (рис. 4).
Рис. 4. Приведение таблицы OrdersInfo к третьей нормальной форме Итак, после приведения исходной таблицы к третьей нормальной форме таблиц стало три - Customers, Orders и OrderDetails.
Преимущества нормализацииНормализация устраняет избыточность данных, что позволяет снизить объем хранимых данных и избавиться от описанных выше аномалий их изменения. Например, после приведения рассмотренной выше базы данных к третьей нормальной форме налицо следующие улучшения:
Изменение адреса клиента или даты регистрации заказа теперь требует изменения только одной записи.
Как проектируют базы данныхОбычно современные СУБД содержат средства, позволяющие создавать таблицы и ключи. Существуют и утилиты, поставляемые отдельно от СУБД (и даже обслуживающие несколько различных СУБД одновременно), позволяющие создавать таблицы, ключи и связи. Еще один способ создать таблицы, ключи и связи в базе данных - это написание так называемого DDL-сценария (DDL - Data Definition Language; о нем мы поговорим чуть позже). Наконец, есть еще один способ, который становится все более и более популярным, - это использование специальных средств, называемых CASE-средствами (CASE означает Computer-Aided System Engineering). Существует несколько типов CASE-средств, но для создания баз данных чаще всего используются инструменты для создания диаграмм <сущность-связь> (entity-relationship diagrams, E/R diagrams). С помощью этих инструментов создается так называемая логическая модель данных, описывающая факты и объекты, подлежащие регистрации в ней (в таких моделях прототипы таблиц называются сущностями (entities), а поля - их атрибутами (attributes). После установления связей между сущностями, определения атрибутов и проведения нормализации, создается так называемая физическая модель данных для конкретной СУБД, в которой определяются все таблицы, поля и другие объекты базы данных. После этого можно сгенерировать либо саму базу данных, либо DDL-сценарий для ее создания. Список наиболее популярных в настоящее время CASE-средств
Объекты баз данныхБольшинство баз данных содержат несколько разных типов объектов, например, таблицы для хранения данных, индексы для сортировки данных и поддержки ключей, ограничения или правила (constraints, rules) для поддержки ссылочной целостности и ограничения значений данных, триггеры (triggers) и хранимые процедуры (stored procedures) для хранения исполняемого кода.
Таблицы и поляТаблицы поддерживаются всеми реляционными СУБД, и в их полях могут храниться данные разных типов. Наиболее часто встречающиеся типы данных
ИндексыЧуть выше мы говорили о роли первичных и внешних ключей. В большинстве реляционных СУБД ключи реализуются с помощью объектов, называемых индексами, которые можно определить как список номеров записей, указывающий, в каком порядке их предоставлять. Мы уже знаем, что записи в реляционных таблицах неупорядочены. Тем не менее любая запись в конкретный момент времени имеет вполне определенное физическое местоположение в файле базы данных, хотя оно и может изменяться в процессе редактирования данных или в результате <внутренней деятельности> самой СУБД. Предположим, в какой-то момент времени записи в таблице Customers хранились в таком порядке.
Допустим, нам нужно получить эти данные упорядоченными по полю CustomerID. Опустив технические детали, мы можем сказать, что индекс по этому полю - это последовательность номеров записей, в соответствии с которой их нужно выводить, то есть: 1,6,4,2,5,3 Если же мы хотим упорядочить записи по полю Address, последовательность номеров записей будет другой: 5,4,1,6,2,3 Хранение индексов требует существенно меньше места, чем хранение по-разному отсортированных версий самой таблицы. Если нам нужно найти данные о клиентах, у которых CustomerID начинается с
символов Мы уже говорили о том, что физическое местоположение записей может изменяться в процессе редактирования данных пользователями, а также в результате манипуляций с файлами базы данных, проводимых самой СУБД (например, сжатие данных, сборка <мусора> и др.). Если при этом происходят соответствующие изменения и в индексе, он называется поддерживаемым и такие индексы используются в большинстве современных СУБД. Реализация таких индексов приводит к тому, что любое изменение данных в таблице влечет за собой изменение связанных с ней индексов, а это увеличивает время, требующееся СУБД для проведения таких операций. Поэтому при использовании таких СУБД следует создавать только те индексы, которые реально необходимы, и руководствоваться при этом тем, какие запросы будут встречаться наиболее часто.
Ограничения и правилаБольшинство современных серверных СУБД содержат специальные объекты, называемые ограничениями (constraints), или правилами (rules). Эти объекты содержат сведения об ограничениях, накладываемых на возможные значения полей. Например, с помощью такого объекта можно установить максимальное или минимальное значение для данного поля, и после этого СУБД не позволит сохранить в базе данных запись, не удовлетворяющую данному условию. Помимо ограничений, связанных с установкой диапазона изменения данных, существуют также ссылочные ограничения (referential constraints, например связь master-detail между таблицами Customers и Orders может быть реализована как ограничение, содержащее требование, чтобы значение поля CustomerId (внешний ключ) в таблице Orders было равно одному из уже имеющихся значений поля CustomerId таблицы Customers. Отметим, что далеко не все СУБД поддерживают ограничения. В этом случае для реализации аналогичной функциональности правил можно либо использовать другие объекты (например, триггеры), либо хранить эти правила в клиентских приложениях, работающих с этой базой данных.
ПредставленияПрактически все реляционные СУБД поддерживают представления (views). Этот объект представляет собой виртуальную таблицу, предоставляющую данные из одной или нескольких реальных таблиц. Реально он не содержит никаких данных, а только описывает их источник. Нередко такие объекты создаются для хранения в базах данных сложных запросов. Фактически view - это хранимый запрос. Создание представлений в большинстве современных СУБД осуществляется специальными визуальными средствами, позволяющими отображать на экране необходимые таблицы, устанавливать связи между ними, выбирать отображаемые поля, вводит ограничения на записи и др. Нередко эти объекты используются для обеспечения безопасности данных, например, путем разрешения просмотра данных с их помощью без предоставления доступа непосредственно к таблицам. Помимо этого некоторые представления объекты могут возвращать разные данные в зависимости, например, от имени пользователя, что позволяет ему получать только интересующие его данные.
Триггеры и хранимые процедурыТриггеры и хранимые процедуры, поддерживаемые в большинстве современных серверных СУБД, используются для хранения исполняемого кода. Хранимая процедура - это специальный вид процедуры, который выполняется сервером баз данных. Хранимые процедуры пишутся на процедурном языке, который зависит от конкретной СУБД. Они могут вызывать друг друга, читать и изменять данные в таблицах, и их можно вызвать из клиентского приложения, работающего с базой данных. Хранимые процедуры обычно используются при выполнении часто встречающихся задач (например, сведение бухгалтерского баланса). Они могут иметь аргументы, возвращать значения, коды ошибок и иногда наборы строк и колонок (такой набор данных иногда называется термином dataset). Однако последний тип процедур поддерживается не всеми СУБД. Триггеры также содержат исполняемый код, но их, в отличие от процедур, нельзя вызвать из клиентского приложения или хранимой процедуры. Триггер всегда связан с конкретной таблицей и выполняется тогда, когда при редактировании этой таблицы наступает событие, с которым он связан (например, вставка, удаление или обновление записи). В большинстве СУБД, поддерживающих триггеры, можно определить несколько триггеров, выполняющихся при наступлении одного и того же события, и определить порядок из выполнения.
Объекты для генерации первичных ключейОчень часто первичные ключи генерируются самой СУБД. Это более удобно, чем их генерация в клиентском приложении, так как при многопользовательской работе генерация ключей с помощью СУБД - это единственный способ избежать дублирования ключей и получать их последовательные значения. В разных СУБД для генерации ключей используются разные объекты. Некоторые из таких объектов хранят целое число и правила, по которым генерируется следующее за ним значение, -обычно это выполняется с помощью триггеров. Такие объекты поддерживаются, например, в Oracle (в этом случае они называются последовательностями - sequences) и в IB Database (в этом случае они называются генераторами - generators). Некоторые СУБД поддерживают специальные типы полей для первичных ключей. При добавлении записей такие поля заполняются автоматически последовательными значениями (обычно целыми). В случае Microsoft Access и Microsoft SQL Server такие поля называются Identity fields, а в случае Corel Paradox - автоинкрементными полями (Autoincrement fields).
Пользователи и ролиПредотвращение несанкционированного доступа к данным является серьезной проблемой, которая решается разными способами. Самый простой - это парольная защита либо всей таблицы, либо некоторых ее полей (такой механизм поддерживается, например, в Corel Paradox). В настоящее время более популярен другой способ защиты данных - создание списка пользователей (users) с именами (user names) и паролями (passwords). В этом случае любой объект базы данных принадлежит конкретному пользователю, и этот пользователь предоставляет другим пользователям разрешение на чтение или модификацию данных из этого объекта либо на модификацию самого объекта. Этот способ применяется во всех серверных и некоторых настольных СУБД (например, Microsoft Access). Некоторые СУБД, в основном серверные, поддерживают не только список пользователей, но и роли (roles). Роль - это набор привилегий. Если конкретный пользователь получает одну или несколько ролей, а вместе с ними - и все привилегии, определенные для данной роли.
Системный каталогЛюбая реляционная СУБД, поддерживающая списки пользователей и ролей, должна их где-то хранить. В дополнение к этим спискам многие СУБД хранят списки таблиц, индексов, триггеров, процедур и др., а также сведения о том, кто ими владеет. Эти списки называются системными таблицами (system tables), а соответствующая часть базы данных называется системным каталогом (system catalog). Отметим, что не все СУБД поддерживают системные каталоги (например, их не поддерживают такие популярные в недавнем прошлом СУБД, как dBase и Paradox).
Запросы к базам данныхМодификация и выбор данных, изменение метаданных и некоторые другие операции осуществляются с помощью запросов (query). Большинство современных СУБД (и некоторые средства разработки приложений) содержат средства для генерации таких запросов. Один из способов манипуляции данными называется В большинстве СУБД (за исключением некоторых настольных) визуальное построение запроса с помощью QBE приводит к генерации текста запроса с помощью специального языка запросов SQL (Structured Query Language). Можно также написать запрос непосредственно на языке SQL.
КурсорыНередко результатом запроса является набор из строк и столбцов (dataset). В отличие от реляционной таблицы в таком наборе строки упорядочены, и их порядок определяется исходным запросом (и иногда - наличием индексов). Поэтому мы можем определить текущую строку в таком наборе и указатель на нее, который называется курсором (cursor). Большинство современных СУБД поддерживают так называемые двунаправленные курсоры (bi-directional cursors), позволяющие перемещаться по результирующему набору данных как вперед, так и назад. Однако некоторые СУБД поддерживают только однонаправленные курсоры, позволяющие перемещаться по набору данных только вперед.
Язык SQLStructured Query Language (SQL) - это непроцедурный язык, используемый для формулировки запросов к базам данных в большинстве современных СУБД и в настоящий момент являющийся индустриальным стандартом. Непроцедурность языка означает, что на нем можно указать, что нужно сделать с базой данных, но нельзя описать алгоритм этого процесса. Все алгоритмы обработки SQL-запросов генерируются самой СУБД и не зависят от пользователя. Язык SQL состоит из набора операторов, которые можно разделить на несколько категорий:
Более подробно о языке SQL вы расскажем в одной из следующих статей этого цикла.
Расширения SQLВыше мы уже отмечали, что триггеры и хранимые процедуры пишутся на процедурном языке, характерном для данной СУБД. В большинстве СУБД такие языки представляют собой процедурные расширения SQL и помимо обычных операторов SQL содержат некоторый набор алгоритмических конструкций, например begin:end, if:then:else и т.д. В отличие от самого языка SQL, подчиняющегося стандарту ANSI, расширения SQL не стандартизованы. У каждой СУБД есть свой диалект процедурных расширений SQL (в СУБД Oracle он называется PL/SQL, в СУБД Microsoft SQL Server - Transact-SQL и т.д.).
Функции, определяемые пользователемНекоторые СУБД позволяют использовать функции, определяемые пользователем (UDF-User-Defined Functions). Эти функции, как правило, хранятся во внешних библиотеках и должны быть зарегистрированы в базе данных, после чего их можно использовать в запросах, триггерах и хранимых процедурах. Поскольку функции, определяемые пользователем, содержатся в библиотеках, их можно создавать с помощью любого средства разработки, позволяющего создавать библиотеки для платформы, на которой функционирует данная СУБД.
ТранзакцииТранзакция (Transaction) - это группа операций над данными, которые либо выполняются все вместе, либо все вместе отменяются. Завершение (Commit) транзакции означает, что все операции, входящие в состав транзакции, успешно завершены, и результат их работы сохранен в базе данных. Откат (Rollback) транзакции означает, что все уже выполненные операции, входящие в состав транзакции, отменяются и все объекты базы данных, затронутые этими операциями, возвращены в исходное состояние. Для реализации возможности отката транзакций многие СУБД поддерживают запись в log-файлы, позволяющие восстановить исходные данные при откате. Транзакция может состоять из нескольких вложенных транзакций. Некоторые СУБД поддерживают двухфазное завершение транзакций (two-phase commit) - процесс, позволяющий осуществлять транзакции над несколькими базами данных, относящихся к одной и той же СУБД. Для поддержки распределенных транзакций (то есть транзакций над базами данных, управляемых разными СУБД), существуют специальные средства, называемые мониторами транзакций (transaction monitors).
ЗаключениеВ данной статье мы обсудили основные концепции построения реляционных СУБД, базовые принципы проектирования данных, а также рассказали о том, какие объекты могут быть созданы в базах данных. В следующей статье мы познакомим наших читателей с наиболее популярными настольными СУБД: dBase, Paradox, Access, Visual FoxPro, Works и обсудим их основные возможности. КомпьютерПресс 3'2000 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
За содержание страницы отвечает Гончарова М.Н. © Кафедра СПиКБ, 2002-2017 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||