|
||||||||
|
||||||||

|
Microsoft SQL Server 2000 Analysis ServicesНаталия Елманова, КомпьютерПресс 9'2000
Что такое OLAP и Analysis Services
В данной статье мы продолжим знакомство с новинками Microsoft SQL Server 2000, начатое в обзоре Алексея Федорова, и обсудим Analysis Services (этот термин иногда переводится как <аналитические службы>) - средства аналитической обработки данных, ранее носившие название OLAP Services (OLAP означает On-Line Analytical Processing), а также новые Data Mining-средства. Изложение темы построено исходя из предположения, что читатель знаком с возможностями Microsoft SQL Server 7.0 OLAP Extensions; тем не менее мы кратко напомним, что такое OLAP. Ниже мы рассмотрим следующие новинки в Microsoft SQL Server 2000 Analysis Services:
Однако начнем мы с краткого объяснения, что такое OLAP и зачем нужна эта технология. Что такое OLAP и Analysis ServicesИнформационные системы масштаба предприятия, как правило, содержат несколько типов автоматизированных рабочих мест для различных категорий пользователей. Особое место среди них занимают приложения, применяемые менеджерами высшего звена и руководителями различных уровней и предназначенные обычно для комплексного многомерного анализа данных, их динамики, тенденций и в конечном итоге - для содействия принятию решений. Подобные приложения, как правило, отличаются по своему интерфейсу от обычных автоматизированных рабочих мест, предназначенных для ввода данных, и в большинстве случаев обладают средствами получения агрегатных данных (сумм, средних, максимальных и минимальных значений для различных выборок). Отметим, что чаще всего рабочее время пользователей таких приложений (иногда они называются системами поддержки принятия решений) ценится весьма высоко, поэтому требования к функциональности и удобству применения здесь намного более важны, чем минимизация их ресурсоемкости. Технология комплексного многомерного анализа данных получила название
OLAP. OLAP - это ключевой компонент организации хранилищ данных (Data
warehousing), то есть сбора, отсеивания и предварительной обработки
данных с целью предоставления результирующей информации пользователям для
статистического анализа и создания отчетов. Концепция OLAP была описана в
1993 году Е.Ф.Коддом, известным исследователем баз данных и автором
реляционной модели данных. Краткое описание многомерного анализа данных
можно найти в статье Многомерный анализ данных может быть осуществлен как в клиентском
приложении (например, средствами многомерного анализа обладает Excel
2000), так и на сервере баз данных. Все производители ведущих серверных
СУБД, такие как Oracle, Microsoft, Informix, IBM, Sybase, производят
серверные средства для подобного анализа, однако соответствующие продукты
Oracle, Informix, IBM и Sybase приобретаются отдельно от сервера баз
данных и стоят довольно дорого. Что же касается Microsoft, то начиная с
версии 7.0 Microsoft SQL Server содержит в своем составе OLAP-сервер и,
таким образом, позволяет создавать относительно недорогие OLAP-решения на
базе Microsoft SQL Server.
Отметим, что приложения, созданные с помощью средств разработки,
поддерживающих OLE DB, могут обращаться к серверным OLAP-хранилищам - для
этой цели в состав Microsoft SQL Server OLAP Services входит OLE
DB-провайдер для SQL Server OLAP Services.
Analysis Services, входящие в состав редакций Enterprise, Standard и
Developer SQL Server 2000, представляют собой дальнейшее развитие
серверных средств Microsoft SQL Server OLAP Extensions. Помимо уже
имеющихся средств построения хранилищ данных и OLAP, Analysis Services в
SQL Server 2000 включают в себя средства Data Mining, новые средства
управления доступом к данным и безопасностью, новые клиентские утилиты для
построения и администрирования многомерных хранилищ и анализа данных, а
также предоставляют новые возможности для администрирования многомерных
хранилищ, создания распределенных хранилищ данных, определения метаданных
(например, размерностей).
Ниже мы более подробно рассмотрим, что представляют собой перечисленные
нововведения. Начнем с новых возможностей, связанных с обеспечением
безопасности данных в многомерных хранилищах.
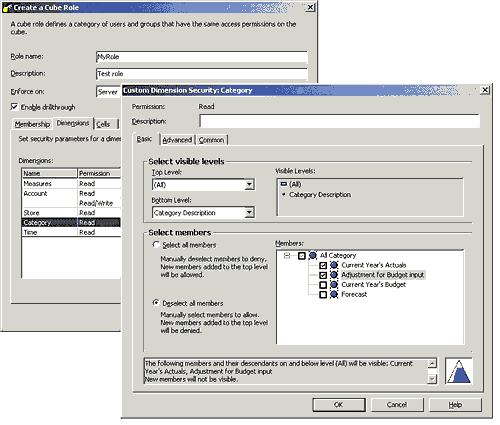
В SQL Server 2000 можно применять роли для регулирования доступа
пользователей к тем или иным размерностям, уровням и членам. Для каждой
роли базы данных или куба можно указать, какие размерности, уровни и члены
видны пользователям при просмотре куба, а также предоставить право записи
в размерности и указать члены, которые может обновлять пользователь,
имеющий данную роль.
Если правила доступа к размерности не определены, то по умолчанию
конечный пользователь может <видеть> все члены данной размерности в кубах,
доступ к которым данному пользователю разрешен, но не может обновлять
члены размерностей.
Правила доступа к размерностям можно определять как на уровне базы
данных, так и на уровне куба. Если правила доступа к размерностям
определены на уровне базы данных, для размерностей, общих для нескольких
кубов (shared dimension), то эти правила будут распространяться на
все кубы, содержащие эту размерность. В ролях, определенных на уровне
куба, имеющиеся правила доступа к размерностям можно переопределять.
Правила доступа к размерностям можно устанавливать для групп
пользователей Windows NT или Windows 2000. Помимо этого имеется
возможность определить члены или группы членов размерности, которые можно
либо нельзя обновлять.
На уровне роли куба можно определить правила доступа к отдельным
ячейкам или группам ячеек в зависимости от того, какие из них доступны
пользователям при просмотре куба и в какие из них разрешена запись (если
данный куб позволяет такие операции).
Если не определены правила доступа к ячейкам и правила доступа к
размерностям, то по умолчанию все ячейки видимы, но недоступны для записи.
Идентификация пользователя на уровне сервера может быть осуществлена
различными методами - они зависят от того, происходит ли доступ
непосредственно к серверу из клиентского приложения или с помощью Internet
Information Services (IIS).
Analysis Manager (клиентская утилита для администрирования многомерных
баз данных в SQL Server 2000) содержит соответствующие диалоговые панели
для управления доступа к данным:
Рис. 1.
Помимо новых возможностей управления доступом к данным, в SQL Server
2000 внесены существенные изменения в реализацию поддержки размерностей
многомерных кубов, а также введены новые типы размерностей.
В SQL Server 2000 изменена поддержка размерностей, содержащих большое
количество членов (10 млн. и более). Теперь размерности могут храниться на
сервере двумя разными способами: в виде либо многомерного хранилища данных
(MOLAP, Multidimensional OLAP), либо таблицы реляционной СУБД
(ROLAP, Relational OLAP). Во втором случае, в отличие от первого,
не накладывается никаких ограничений на количество членов размерности.
Максимальное число размерностей куба теперь равно 128 (в прежней версии
- 64). Максимальное число уровней иерархии в SQL Server 2000 также равно
128.
Значения ячеек куба (или группы ячеек для определенного уровня в
размерности), вычисляемые на основе агрегатных функций, теперь могут быть
переопределены - вместо них можно использовать MDX-выражения (MDX,
Multidimensional Expressions - расширение языка SQL,
предназначенное для запросов к многомерным базам данных). Например, имея
иерархическую размерность c уровнями Year и Quarter и
соответствующие им данные в ячейках следующего вида:
мы можем переопределить правило, по которому вычисляется агрегатная
функция Sum, следующим образом:
Это приведет к такому набору значений для членов уровня Year:
Еще одним новшеством SQL Server 2000 Analysis Services является
возможность группировки членов, то есть создания автоматически
генерируемого члена-родителя для набора членов на уровне, непосредственно
предшествует уровню, содержащему данный набор. Подобная группировка
позволяет использовать иерархии, члены которых имеют более 64 тыс.
дочерних членов, за счет снижения их количества путем создания
промежуточного уровня с группами.
В SQL Server 2000 для каждой размерности можно по умолчанию определить
значение члена, зависящее от роли, что позволяет влиять на то, какие
данные <видит> пользователь, просматривая куб, содержащий эту размерность.
Для ограничения строк таблицы, включаемых в размерность, в SQL Server
2000 можно использовать фильтры (выражения с ключевым словом
WHERE). Фильтр определяется с помощью свойства размерности
Source Table Filter.
Изменена поддержка виртуальных размерностей. В SQL Server 2000
отсутствуют ограничения на число членов такой размерности (в предыдущей
версии это число не должно было превышать 760).
Помимо этого в SQL Server 2000 Analysis Services введены новые типы
размерностей:
рис. 2. рис. 3. Однако наиболее революционным нововведением в SQL Server 2000 являются
средства Data Mining. Ниже мы обсудим, зачем они нужны и что они собой
представляют.
Как было сказано выше, средства Data Mining являются составной частью
Analysis Services в версиях Microsoft SQL Server 2000 Enterprise,
Standard, Personal и Developer.
Корпоративная база данных предприятия обычно содержит набор таблиц,
хранящих сведения о тех или иных фактах (например, для торгового
предприятия это могут быть факты продажи какого-либо товара). Каждая
запись такой таблицы содержит лишь сведения о подобном факте (например,
что конкретный товар был продан конкретному клиенту из конкретного региона
в конкретные день и время конкретным менеджером), и не более того. Однако
совокупность таких записей, накопленных за несколько лет, может служить
источником дополнительной информации, которую нельзя получить на основе
одной конкретной записи. Это могут быть сведения о том, какова динамика
продаж какого-либо товара, как объем продаж того или иного товара зависит
от сезона, дня недели, времени суток, а также иные сведения, позволяющие
определять закономерности и тенденции, делать на их основе прогнозы и
принимать управленческие решения. Ценность такой информации для
предприятия может быть очень высока, и, видимо, поэтому процесс ее поиска
и получил название Data Mining. Слово Иными словами, термин Data mining означает поиск закономерностей,
корреляций и тенденций в данных.
Подобный поиск может быть осуществлен как в реляционных, так и в
многомерных базах данных (например, созданных с помощью самих Analysis
Services), а результаты этого поиска могут быть использованы для создания
новых размерностей OLAP-кубов для дальнейшего OLAP-анализа либо для
запросов к реляционным базам данных.
Для поддержки Data Mining внесены изменения в объектные модели
клиентской части Analysis Services - Decision Support Objects (DSO)
и PivotTable Service, что позволяет использовать эти сервисы в
приложениях, созданных с помощью различных средств разработки. Отметим
также, что с целью поддержки применения средств Data Mining в приложениях
создана новая спецификация для OLE DB-провайдеров соответствующего типа -
OLE DB for Data Mining (в дополнение к уже имеющейся спецификации OLE DB
for OLAP).
SQL Server 2000 содержит два класса алгоритмов Data Mining,
разработанных в Microsoft, - Microsoft Decision Trees и
Microsoft Clustering.
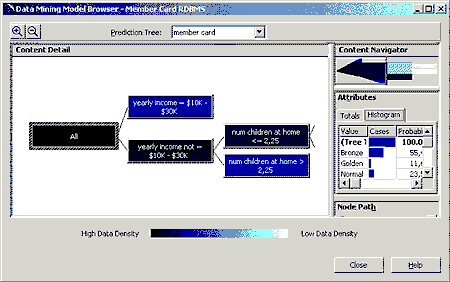
Алгоритм Microsoft Decision Trees содержит четыре разных
алгоритма и основан на понятии классификации. Он строит <дерево>
(decision tree), позволяющее предсказать значения в одних полях на
основе значений в других полях таблицы фактов (получившей название
training set). Алгоритмом Microsoft Decision Trees принимается
решение о том, куда поместить каждую ветвь дерева, и при этом наиболее
важные атрибуты помещаются как можно ближе к корню дерева:
рис. 4.
Реализация алгоритма Microsoft Decision Trees может быть использована
для определения тех или иных категорий атрибутов и фактов (например, для
определения категорий покупателей, наиболее часто приобретающих конкретный
товар).
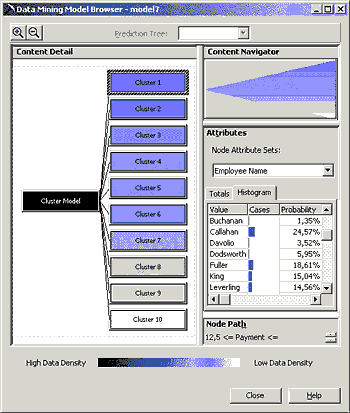
Алгоритм Microsoft Clustering использует метод <ближайшего
соседа> (метод, группирующий в кластеры записи, имеющие сходные
характеристики. Нередко эти характеристики могут быть неочевидными или
скрытыми, например зависимость стоимости покупок от возраста или пола
покупателя):
рис. 5
Помимо перечисленных выше алгоритмов Data Mining, SQL Server 2000
позволяет использовать алгоритмы, разработанные сторонними
производителями.
Отметим, что наличие Data Mining-средств в Analysis Services делает
решения на их основе сравнимыми с решениями других производителей
серверных СУБД и средств анализа данных (SPSS, SAS Institute, Cognos,
Syllogic) при гораздо более привлекательной стоимости.
Изменения в возможностях серверной части Analysis Services повлекли за
собой и соответствующие нововведения в их клиентской части. Ниже мы
рассмотрим, что нового появилось в PivotTable Services - библиотеках,
используемых OLAP-клиентами.
PivotTable Service представляет собой OLE DB-провайдер для многомерных
баз данных и операций Data Mining. Он используется приложениями,
нуждающимися в доступе к этим данным и сервисам (в частности, Microsoft
Excel 2000), и поддерживает извлечение данных из многомерных баз данных с
помощью языка запросов MDX и создание локальных кубов (файлов с
расширением *.cub).
В SQL Server 2000 клиентские приложения, использующие PivotTable
Service, могут соединяться с сервером посредством Microsoft Internet
Information Services (IIS) с помощью протокола HTTP.
PivotTable Service поддерживает анализ данных с помощью алгоритмов Data
Mining. Модели Data Mining интерпретируются им как многомерные кубы, что
позволяет создавать локальные модели Data Mining, получая для них
информацию из кубов, хранящихся на сервере.
PivotTable Service поддерживает обновление серверных кубов с помощью
команды UPDATE CUBE. Что касается локальных кубов, то клиентские
приложения могут изменять их структуру, определять члены по умолчанию и
изменять порядок сортировки членов в иерархиях с помощью команды ALTER
CUBE.
Помимо рассмотренных выше изменений, Analysis Services содержат еще ряд
нововведений, позволяющих, в частности, создавать распределенные хранилища
данных и более гибко управлять производительностью OLAP-приложений.
Рассмотрим некоторые другие нововведения в Microsoft SQL Server 2000
Analysis Services:
рис. 6 Это повышает масштабируемость распределенных OLAP-приложений, так как
при администрировании удаленных разделов и осуществлении запросов к ним
потребляются в основном ресурсы удаленного сервера. В данной статье мы ознакомили вас с новыми возможностями SQL Server
2000 Analysis Services: нововведениями в средствах управления доступом к
данным, новыми типами размерностей и изменениями в их поддержке,
изменениями в клиентских утилитах и PivotTable Service. Кроме того, мы
рассказали о наиболее существенном нововведении - поддержке Data Mining, а
также о средствах создания распределенных многомерных хранилищ данных.
Отметим, однако, что подробное описание всех нововведений в Analysis
Services невозможно поместить в одну статью, поэтому мы предполагаем
вернуться к этой теме после выпуска окончательной версии SQL Server 2000.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
За содержание страницы отвечает Гончарова М.Н. © Кафедра СПиКБ, 2002-2017 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||