|
||||||||
|
||||||||

|
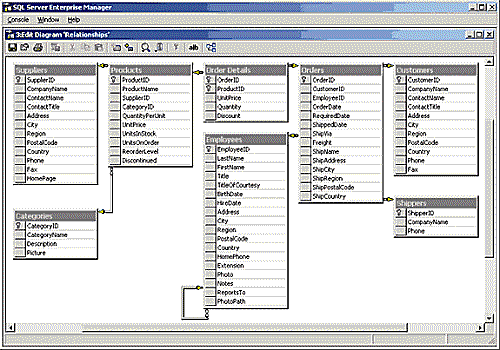
От реляционного к многомерномуБоб Пфайф, SQL Magazine OnLine #01/2001 Термины "витрина данных", "многомерная база данных", "схема звезды", наверное, встречались читателям, но для большинства они все еще остаются несколько загадочными. Если вам не приходилось принимать участие в создании хранилища данных для всего предприятия, или витрины данных для какого-либо его подразделения, то понять ключевые концепции хранилищ данных и возможности их применения в бизнесе окажется не так-то просто. Поэтому весь ход обсуждения методики создания хранилищ данных, которой посвящена данная статья, будет проиллюстрирован примером из жизни. В этом качестве выступает распространенная в среде бизнеса задача построения витрины данных. В рассматриваемом примере витрина данных будет основываться на хорошо знакомой читателям учебной базе данных Northwind, входящей в состав SQL Server. СценарийПредположим, что я работал в Northwind Traders Inc. администратором базы данных или разработчиком программного обеспечения, то есть, был тем самым сотрудником подразделения ИТ, к которому все обращаются, когда надо что-то сделать. Предположим, что в один прекрасный день доктор Эндрю Фуллер, вице-президент компании, отвечающий за продажи, обратился ко мне с вопросом об объемах продаж товаров в Northwind Traders: "Мне бы хотелось получить информацию о том, сколько каких товаров было заказано покупателями в Соединенных штатах в 1997 году. Поквартально. И дайте-ка мне сведения о трех лучших продавцах и их менеджерах". "Будет сделано", - ответил я, потому что знал, что вся нужная информация содержится в системе обработки заказов. Сведения о клиентах, товарах, заказах, поставщиках, служащих - все хранится в реляционной базе данных нашей компании. Она приведена к третьей нормальной форме, как показано на экране 1. Тогда я только что закончил настраивать базу данных так, чтобы все вводимые заказы обрабатывались как можно быстрее. И вот шеф захотел, чтобы параллельно с вводом заказов началось составление отчетов, которые требуют много вычислительных ресурсов. Задача ввода заказов стала бы конкурировать с задачами формирования отчетов, так что скорость обработки заказов опять упала бы.
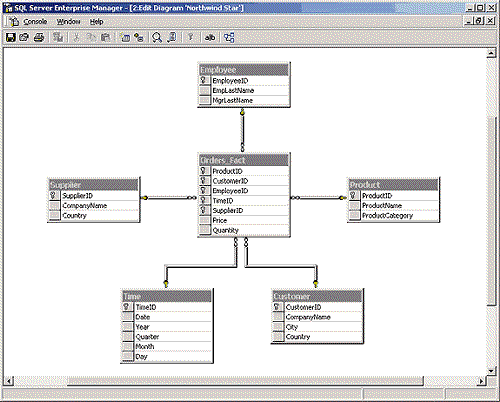
Я решил узнать, как доктор Фуллер и его сотрудники собираются воспользоваться запрошенной информацией. Из разговора с менеджером и сотрудниками отдела продаж я понял, что "сколько каких товаров было заказано покупателями в Соединенных штатах" означало два параметра - количество и стоимость заказанных товаров, то есть речь шла об информации, содержащейся в таблице Order Details. Доктор Фуллер хотел получить сведения "за 1997 год, поквартально", то есть мне предстояло отфильтровать информацию по времени. Пожелание вице-президента иметь "сведения о трех лучших продавцах" говорило о том, что данные об объемах продаж надо сгруппировать так, чтобы их было легко поставить в соответствие служащим отдела продаж. Менеджер этого отдела сказал мне, что вся эта информация нужна доктору Фуллеру каждый вторник к началу утреннего совещания по продажам. Иными словами, ему не требовалось получать данные оперативно, с точностью до минуты. Что ж, это оставляло возможность сохранить производительность системы ввода заказов на высоком уровне. Проект решенияПоскольку от меня требовалось агрегировать данные об объемах продаж по времени с учетом ответственных за сделки торговых представителей, я начал продумывать новую структуру данных, которая лучше подходила бы для составления отчетов. Пришлось потратить некоторое время на изучение подходов к построению хранилищ данных, включая изучение классического труда Ральфа Кимбала (Ralph Kimball "The Data Warehouse Toolkit: Practical Techniques for Building Dimensional Data Warehouses", John Wiley & Sons, 1996). В конце концов, я решил использовать многомерную модель для построения нового типа базы данных - витрины данных, data mart. Витрина данных, позволяющая пользователям из производственных отделов компании получать доступ к информации своего подразделения и анализировать ее, оказалась самым подходящим решением, полностью отвечающим потребностям отдела продаж. Я решил, что витрина должна содержать только сведения о продажах, а ее пользователями могут быть только сотрудники данного отдела. Помимо этого, применение витрины данных позволило бы исключить конкуренцию системы обработки заказов, действующей в реальном времени, с задачами формирования отчетов. Ведь загрузка в витрину данных информации из оперативной системы происходила бы только по расписанию. Кроме того, я смог бы уменьшить число операций соединения, необходимых для формирования отчетов, и построить индексы для ускорения обработки запросов. Исходя из требований доктора Фуллера и пожеланий сотрудников отдела продаж, я определил для витрины данных ее размерности, dimensions, и показатели, measures. Показатели представляют собой критерии ведения бизнеса, например, долларовое выражение объемов продаж, а размерности соответствуют компонентам, которые пользователи применяют в запросах при обращении к показателям. К размерностям относятся, например, время или торговый представитель, ответственный за сделку. Часто приходится слышать: "Мне бы хотелось увидеть то-то, представленное так-то". В этом случае следует понимать, что обычно "то-то" является кандидатом в показатели, а "так-то", скорее всего, станет элементом размерности. Иерархии размерностей в системах оперативной обработки обычно просты и понятны. К примеру, размерность Товар, Product, содержит категорию продукта и его название. В иерархию размерности Заказчик, Customer, помимо имени заказчика входят страна и город, где он живет. В исходной базе данных заполненные поля, в которых должен был указываться регион поставщика, встречались очень редко, поэтому в новую базу данных вошли только страна и имя поставщика. С учетом этих основных зависимостей у меня получился проект многомерной базы данных, представленный на экране 2.
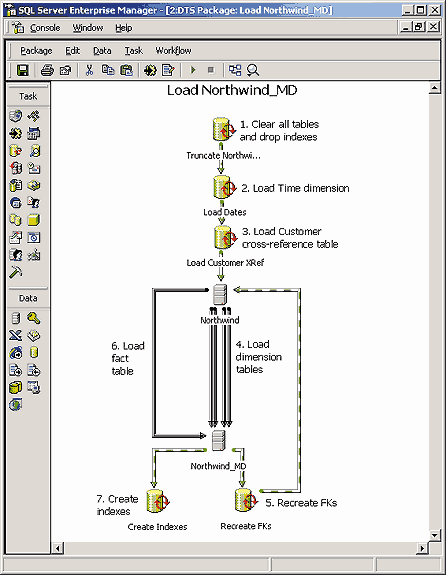
Чтобы обеспечить гибкость, необходимую при составлении отчетов, и высокое быстродействие при обработке запросов, я заранее выполнил соединение фактографической таблицы Orders_Fact, в которой содержатся сведения о продажах, с таблицами размерностей. Кроме того, при помощи запросов я произвел фильтрацию и группировку данных размерностей. Чтобы еще увеличить производительность витрины, были построены индексы для всех внешних ключей в таблице Orders_Fact. А для сохранения целостности сущностей на базе комбинации всех внешних ключей был построен первичный ключ. В результате всех этих проектных решений появилась база данных, которая уже могла служить основой для витрины данных, использующей оперативную информацию о заказах. Но в этой многомерной базе данных все еще оставались реляционные черты: ограничения внешнего ключа, связывающие фактографическую таблицу с таблицами размерностей, а также ограничения первичного ключа во всех таблицах. Чтобы избавиться от этого, я провел денормализацию базы данных, скомбинировав несколько таблиц исходной базы данных. В результате получилась база данных, построенная по схеме звезды. Это название обязано своим происхождением внешнему виду диаграммы сущность-связь, соответствующей такой базе данных. К примеру, моя база данных выглядела на экране 2 как пятиконечная звезда. Основное достоинство схемы звезды состоит в том, что ее размерности очень просто использовать при формировании запросов относительно ее показателей. При проведении денормализации базы данных я объединил таблицу заказов, Orders, с таблицей пунктов заказов, Order Details, в одну таблицу Orders_Fact, содержащую сведения обо всех пунктах каждого заказа. Таблице Orders_Fact соответствует наибольшая глубина детализации данных о заказах. Это обеспечило необходимую гибкость при составлении отчетов. Аналогичным образом я скомбинировал таблицы Products и Categories в одну таблицу размерности Товар, Product. Если бы я сохранил нормализованные отношения этих двух таблиц в таблице размерности Товар, тем самым я частично ввел бы в схему своей базы данных элементы схемы "снежинка". Она получила свое название из-за внешнего сходства диаграммы нормализованной базы данных со снежинкой. Но я решил применить схему звезды, а не снежинки, потому что иначе пришлось бы выполнять больше операций соединения при обработке запросов к фактографической таблице. На стадии проектирования следовало также провести ревизию ключей таблиц размерностей и фактов. В исходной системе в таблице Customers столбец CustomerID, содержащий идентификаторы заказчиков, определялся как символьный. Я же отнес его к числовому типу по двум причинам. Во-первых, для повышения производительности я всегда предпочитал индексировать и выполнять соединения не символьных, а числовых величин. Во-вторых, чем меньше многомерная база данных зависит от исходной системы, тем выше вероятность, что изменения в исходной системе не повлекут за собой изменения многомерной структуры. В целях демонстрации подхода я изменил тип данных только для столбцов CustomerID и TimeID размерностей заказчиков и времени. В остальных размерностях числовые ключи были использованы и в исходной оперативной системе ввода заказов. Загрузка витрины данныхТеперь мне предстояло решить, как будет происходить загрузка информации в многомерную витрину из оперативной базы данных. Процесс переноса информации из одной структуры данных в другую называется ETL, по первым буквам слов извлечение (Extraction), преобразование (Transformation) и загрузка (Loading). Поскольку в рассматриваемом примере для формирования таблицы фактов продаж и некоторых таблиц размерностей использовались данные нескольких таблиц исходной системы, и при этом должно было проводиться преобразование символьных значений столбца CustomerID в числовой вид, в этом проекте необходимо было задействовать некоторые составляющие процесса ETL. Для переноса данных я разработал состоящий из семи частей пакет DTS (Data Transformation Services), показанный на экране 3.
В исходной системе информация была хорошо сформирована, поэтому мне не пришлось тратить много времени на очистку данных и их преобразование. Но в действительности все обстоит не так гладко. В приложении "Преобразование данных в реальном мире", помещенном в конце данной статьи, кратко рассказано о том, каково на самом деле качество сведений, которые должны попасть в витрины и хранилища данных. На экране 3 приняты следующие обозначения: стрелки показывают последовательность выполнения задач, а пунктирные бело-зеленые стрелки соответствуют действиям, предпринимаемым пакетом в случае успешного завершения предыдущего шага. Этот пакет DTS использует два соединения с SQL Server: одно для связи с оперативной базой данных Northwind, а другое - для связи с многомерной витриной данных Northwind_MD. Пройдемся по всем семи задачам рассматриваемого пакета. Шаг 1. Начинает процесс задача T-SQL, которая выполняет две функции: снимает ограничения внешнего ключа и ликвидирует индексы фактографической таблицы. Первое действие позволяет усекать все таблицы в многомерной базе данных, а второе в дальнейшем существенно ускорит загрузку. Можно было бы написать другой пакет, который осуществлял бы, например, пополнение витрины данных новой порцией информации о заказах, сделанных в течение недели. Шаг 2. Затем идет другая задача T-SQL, которая загружает размерность Время, вставляя подряд все даты в заданном временном интервале. Как показано в листинге 1, эта задача использует разбиение года на кварталы, месяцы и дни, реализуя, таким образом, иерархию промежутков времени, применяемую доктором Фуллером и сотрудниками отдела продаж при анализе данных. /* Листинг1 - эта задача загружает в размерность Time даты в интервале от 1 января 1995 до 31 декабря 1999*/ declare @date smalldatetime set @date = `1995-01-01` while @date < `2000-01-01` begin insert [time] (date, year, quarter, month, day) values (@date, year(@date), `Q` + convert(varchar, datepart(q, @date)), datename(month, @date), day(@date)) set @date = dateadd(dd, 1, @date) end Шаг 3. После этого я написал задачу T-SQL, которая загружала в таблицу перекрестных ссылок символьные значения из столбца CustomerID таблицы Customer с информацией о заказчиках, как видно из листинга 2. В таблице перекрестных ссылок Customer_Xref предусмотрен также столбец числового типа, у которого активизировано свойство идентификации, генерирующее значения суррогатных ключей для заказчиков. /*Листинг 2: загрузка таблицы перекрестных ссылок для переноса ключей CustomerID из базы данных Northwind в многомерную базу данных Northwind_MD*/ insert into customer_xref select customerid from northwind..customers Шаг 4. На этом шаге выполняются четыре задачи переноса данных, отмеченные на экране 3 серыми линиями. Они загружают оставшиеся таблицы размерностей из базы данных Northwind. Эти задачи используют соединения с SQL Server для переноса данных между базами данных Northwind и Northwind_MD. Просмотреть каждую задачу перекачки данных можно в пакете DTS, который входит в состав кода, сопровождающего оригинал статьи 8563, размещенной в сети по адресу http://www.sqlmag.com/. Здесь рассмотрена только задача заполнения размерности Заказчик, Customer, в частности, генерация суррогатных ключей для заказчиков. В листинге 3 приведен запрос, исполняющий роль источника данных при загрузке размерности Заказчики. /*Листинг 3: загрузка в размерность Customer информации из таблицы Customer_XRef и таблицы Customers базы данных Northwind*/ select x.destcustomerid, c.companyname, c.city, c.country from northwind..customers as c join northwind_md..customer_xref as x on c.customerid = x.sourcecustomerid Напомним, что в таблице перекрестных ссылок Customer_Xref имеются два значения ключа заказчика: символьное значение ключа CustomerID из исходной системы оперативного ввода заказов (столбец SourceCustomerID), а также сгенерированное системой цифровое значение (DestCustomerID). Поэтому источником для задачи перекачки данных служит запрос, выполняющий соединение таблицы Customer базы данных Northwind с таблицей Customer_Xref многомерной базы данных Northwind_MD. Он переносит числовые значения столбца DestCustomerID в таблицу Customer базы данных Northwind_MD. Создание таблиц наподобие Customer_Xref очень полезно при преобразованиях и интеграции данных в ходе выполнения процесса ETL. Здесь приведен очень простой пример, а мне приходилось строить целые базы данных, содержащие такие вспомогательные таблицы, предназначенные для более сложных интегральных преобразований. Другие задачи перекачки данных также используют в качестве источников данных запросы. В демонстрационных целях для форматирования информации в многомерной базе данных они используют сценарии ActiveX или преобразования Copy Column. Преобразования Copy Column работают быстрее, чем сценарии ActiveX, так как последние обрабатывают данные построчно. Если все же придется воспользоваться средствами ActiveX, то рекомендуется для ускорения обработки обозначать столбцы не именами, а числами, как показано в листинге 4 для задачи перекачки данных о служащих (таблица Employees).
`Листинг 4: сценарий преобразований на ActiveX
`*****************************************************
` Visual Basic Transformation Script
` Копирует каждый исходный столбец
` в результирующий столбец
`******************************************************
Function Main()
DTSDestination("EmployeeID") = DTSSource("employeeid")
`ссылки в виде чисел эффективнее, чем имена (0-based ordinals)
DTSDestination(2) = DTSSource(2)
DTSDestination("MgrLastName") = DTSSource("manager")
Main = DTSTransformStat_OK
End Function
Шаг 5. После завершения загрузки реляционных данных в многомерные таблицы необходимо восстановить ограничения внешнего ключа. Это выполняется отдельной задачей T-SQL. Шаг 6. Для загрузки фактографической таблицы применяется другая задача перекачки данных. В листинге 5 приведен запрос, играющий роль источника данных для этой задачи. /*Листинг 5: Запрос для загрузки фактографической таблицы Orders_Fact Загрузка данных в Orders_Fact из таблиц Orders и Order Details базы данных Northwind с использованием таблицы Customer_XRef и размерности Time для ввода суррогатных ключей TimeID и CustomerID*/ select od.productid, x.destcustomerid, o.employeeid, t.timeid, p.supplierid, od.unitprice, od.quantity from [order details] as od join orders as o on od.orderid = o.orderid join products as p on od.productid = p.productid join northwind_md..customer_xref as x on o.customerid = x.sourcecustomerid join northwind_md..time as t on o.orderdate = t.date Он соединяет таблицы заказов, Orders, и пунктов заказов, Order Details, из базы данных Northwind с таблицами размерностей и перекрестных ссылок многомерной базы данных Northwind_MD. Как я уже говорил ранее, я немного схитрил, взяв в качестве ключей таблиц товаров, поставщиков и служащих цифровые значения из базы данных Northwind, и просто поместив их в базу данных Northwind_MD. Обратите внимание на соединение таблицы Orders из базы данных Northwind с таблицей Time многомерной базы данных Northwind_MD. Оно необходимо для того, чтобы воспользоваться цифровыми значениями ключа TimeID размерности Время. Шаг 7. На последнем этапе для ускорения обработки запросов к многомерной базе данных строятся индексы для внешних ключей таблицы Orders_Fact. На этом построение моей многомерной базы данных завершено. ОпробацияПо окончании загрузки многомерной базы данных я попробовал ответить на один из вопросов доктора Фуллера: "Мне бы хотелось получить информацию о том, сколько каких товаров было заказано покупателями в Соединенных штатах в 1997 году. Поквартально." В листинге 6 показан запрос к витрине данных Northwind_MD, который надо запустить для ответа на этот вопрос. /* Листинг 6: Запрос количества заказанных товаров из многомерной витрины данных */ use northwind_md select t.quarter, p.productcategory, sum(o.quantity) as quantity from orders_fact as o join product as p on o.productid = p.productid join customer as c on o.customerid = c.customerid join time as t on o.timeid = t.timeid where t.year = 1997 and c.country = `usa` group by t.quarter, p.productcategory order by t.quarter, p.productcategory В листинге 7 приведен запрос, необходимый для получения соответствующих сведений из оперативной базы данных Northwind. /* Листинг 7: Запрос количества заказанных товаров из реляционной базы данных */ Хотя оба запроса возвращают одни и те же результаты, в запросе к витрине данных используется на одну операцию соединения меньше, чем в запросе к базе данных Northwind. Кроме того, запрос T-SQL к витрине данных выглядит проще за счет того, что при ее проектировании уже были учтены особенности представления данных для деловых людей. Еще одним достоинством витрины является то, что за получением информации не пришлось обращаться к оперативной системе ввода заказов, и без того перегруженной обработкой транзакций. Все перечисленные преимущества использования витрин данных еще ярче проявляются при работе в среде, насыщенной разнообразными задачами. Рассмотренный в данной статье простой пример иллюстрирует эффективный путь компоновки оперативных данных в виде, удобном для тех сотрудников, которые должны принимать решения. При таком подходе доступ к информации о бизнесе осуществляется легко. Но на этом все не заканчивается. К примеру, для доступа к витрине данных можно было бы воспользоваться средствами Microsoft OLAP Services или другими аналитическими программами. Инструментарий OLAP в состоянии улучшить время реакции системы в результате предварительного агрегирования данных. Кроме того, многие средства OLAP обеспечивают хороший пользовательский интерфейс, так что для проведения анализа данных и формирования отчетов не требуется уметь программировать. Если вас заинтересовало использование схемы звезды, то вы сможете оценить ее широчайшие возможности, особенно при построении многомерных кубов данных, к которым конечные пользователи смогут обращаться с запросами в интерактивном режиме. В качестве дальнейших шагов в этом направлении попробуйте построить из многомерной базы куб данных OLAP при помощи OLAP Services Cube Wizard, а затем воспользоваться дополнительными средствами DTS Processes Cube для обновления куба по заранее составленному расписанию. Можно научить конечных пользователей отвечать на их собственные вопросы при помощи инструментария OLAP или входящей в состав Excel утилиты вращения таблиц PivotTable Services. ПриложениеПреобразование данных в реальном миреБудьте готовы к тому, что при создании реальных хранилищ данных, использующих разрозненные источники информации, никогда не удастся встретить такие "чистенькие" данные, как в базе Northwind. Мне приходилось извлекать данные из унаследованных старых систем, у которых не было ни доменов, ни сущностей, и даже не сохранялась целостность ссылок. Однажды мне довелось обнаружить фрагменты имен клиентов в столбце, где предполагалось хранить даты. В другой системе мне не удалось найти способ установить соответствие между заказчиками и счетами, которыми им выписывались, хотя с точки зрения бизнеса это нонсенс, поскольку такая связь непременно должна прослеживаться. В данной статье я намеренно рассматривал простой проект, дабы облегчить понимание основных концепций. Но эта простота не должна вводить в заблуждение относительно качества данных, трудностей интеграции и управления, с которыми приходится сталкиваться в подавляющем большинстве случаев при создании хранилищ данных. Построение витрины данных и присоединение к ней инструментария OLAP для проведения анализа и составления отчетов - это лишь верхушка айсберга. А огромную невидимую подводную его часть, то есть этап проектирования и внедрения хранилища, составляют такие процессы, как обеспечение качества данных, анализ жизненного цикла хранилища, интеграция и извлечение данных, преобразование и загрузка информации, принятие проектных решений и решений по развертыванию хранилища, а также управление метаданными. Не позволяйте этим монстрам застать вас врасплох. Боб Пфайф (robertp@crosstier.com) является одним из руководителей CrossTier.com. Специалист по базам данных, имеет опыт работы в области создания хранилищ данных, разработки сетевых приложений и приложений для электронной коммерции между предприятиями, а также настройки производительности программных систем. Сертифицирован как MCDBA, MCSD, MCSE, MCT, имеет статус SQL Server MVP. | ||||||||||
|
За содержание страницы отвечает Гончарова М.Н. © Кафедра СПиКБ, 2002-2017 |
|||||||||||