|
||||||||
|
||||||||

|
Средства исследования данных в SQL Server 2000. Часть 2.
Барри де Виль, SQL Server Magazine ONLINE #3/2001 Продолжение рассказа о новых возможностях аналитических служб и применяемых
алгоритмах.
Как происходит процесс исследования данных
Подлежащие исследованию данные представляют собой набор таблиц. В примере,
который будет рассмотрен ниже, объект данных включает таблицу заказчиков,
которая связана с таблицей рекламных приемов продвижения товаров, и обе эти
таблицы связаны с таблицей, содержащей сведения об участниках конференций. Это
типичный сценарий исследования данных, в котором информация о реакции клиентов
на предыдущие рекламные компании используется для обучения DM-модели выявлять
характеристики клиентов, которые с наибольшей вероятностью откликнутся на новые
приемы продвижения товаров. В процессе исследования данных сначала для
идентификации исторических шаблонов поведения используются обучающие процедуры,
а затем полученные шаблоны применяются для предсказания поведения. Подобное
прогнозирование осуществляется при помощи специального оператора исследования
данных. Его можно реализовать средствами Data Transformation Services (DTS).
DTS предоставляет простой инструмент формирования запросов, позволяющий строить
прогнозирующий пакет. Такой пакет содержит обученную модель DM и указание на
источник неисследованных данных, относительно которых желательно получить
прогноз. Предположим, к примеру, что некоторый источник данных был использован
для поиска шаблонов, предсказывающих вероятную реакцию заказчиков на получение
приглашения на конференцию. Тогда можно было бы использовать DTS для того,
чтобы применить этот прогнозирующий шаблон к новому источнику данных, с целью
оценки числа заказчиков, которые откликнутся на приглашение. Уже имеющиеся в
DTS механизмы развертывания моделей исследования данных служат основой для
объединения средств DM, бизнес-интеллекта и хранилищ данных в среде Microsoft. Коллекция данных, составляющих единую сущность (например, заказчика)
представляет собой дело или случай. Множество взаимосвязанных
случаев (заказчиков, приемов продвижения товаров, конференций) образует набор
дел. В OLE DB for Data Mining применяются вложенные таблицы, то есть таблицы,
находящиеся внутри других таблиц. Этот термин соответствует определению,
выработанному службой формирования данных, Data Shaping Service, которая
является составной частью Microsoft Data Access Components (MDAC). К примеру,
можно хранить данные о закупках товаров в деле заказчика. В спецификации OLE DB
for Data Mining для осуществления подобного вложения используется оператор
SHAPE. Важным достоинством средств исследования данных в SQL Server 2000 является
простота их развертывания. При помощи DTS можно легко применять предварительно
обученнные модели в исследовании новых источников данных. Стратегия Microsoft
заключается в том, чтобы сделать программные продукты для исследования данных
похожими на классические средства обработки данных. Тогда пользователи смогут
извлекать данные, манипулировать ими и анализировать их так же, как они делают
это с информацией из таблиц типичных баз данных. Такой подход базируется на
принятой в компаниях практике, при которой DM-аналитик обычно работает вне
стандартных реляционных баз данных. Когда исследования проводятся вне рабочей
БД, обычно создается новая база данных. Это приводит к избыточности, создает
предпосылки для возникновения ошибок и отнимает время. В связи с этим основной
задачей разработки SQL Server 2000 была интеграция механизмов исследования
данных непосредственно в базу данных, так чтобы DM-модель была таким же обычным
объектом базы данных, как и таблица. Если предлагаемый подход будет принят в
промышленности, он поможет оптимизировать построение хранилищ данных специально
с целью исследования содержащихся в них сведений. Этот подход также позволит
сэкономить время и избежать возможного нарушения целостности данных.
Возможность порчи данных связана с необходимостью строить отдельную базу данных
для DM-исследований. Наконец, исследование данных "на месте" (так
называется применение исходных БД для проведения DM-исследований) позволит
работать без дополнительной задержки. По мере роста потребности в разработке
новых DM-продуктов и в усовершенствовании старых именно фактор времени может
стать решающим для реализации концепции встраивания функций DM в ядро систем
управления базами данных (СУБД). Задачи исследования данных в Analysis Services
Методы DM можно использовать для решения широкого круга задач, но все они
могут быть разделены на три категории: модели прогнозирования, кластерные
модели и модели аффинности (сродства). Модели прогнозирования (в Microsoft для
них принято еще название моделей классификации) помогают предсказывать или
классифицировать результаты на основании одного или нескольких полей или
переменных в наборе данных. Кластерные модели, иногда называемые также моделями
сегментации, применяются для объединения сходных записей в группы на основании
разделяемых значений множества полей в наборе данных. Модели аффинности -
включая анализ последовательностей, а также ассоциацитивный и дисперсионный
анализ - вместе с моделированием зависимостей обычно показывают взаимосвязи
полей и устанавливают их последовательность. В аналитической службе SQL Server
2000 (Analysis Services) реализованы два базовых алгоритма, поддерживающие
классификацию и кластеризацию: деревья решений и кластерный анализ. Прогнозирование
при помощи деревьев решений. При моделировании результатов для предсказания или классификации значений
целевой переменной (отклика, результата) используется ряд входных переменных.
Целевая переменная может быть либо дискретной (то есть обладать дискретным
набором значений, таких как "есть отклик/нет отклика"), либо
непрерывной (например, выражать сумму продаж товаров в долларах). В тех
случаях, когда целевая переменная является дискретной, модель решает задачу
классификации, иными словами, показывает, какие комбинации входных
переменных можно использовать для достоверной классификации целевой переменной.
Когда целевая переменная является непрерывной, модель обычно описывается как регрессионная.
Регрессия - самый популярный способ анализа, при котором значения непрерывной
целевой переменной прогнозируются исходя из комбинаций значений входных
переменных. Для простоты специалисты Microsoft используют термин классификация
для обоих типов задач - и классификации, и регрессии. Если вас это смущает,
просто помните, что деревья решений могут предсказывать или классифицировать
целевые переменные как дискретного типа (обладающие набором из нескольких
значений), так и непрерывного типа (обладающие целым множеством возможных
значений). Деревья решений представляют собой широко распространенную и надежную
технологию решения задач моделирования с целью получения прогнозов, в которой
применяется поле исходов для тренировки (обучения). С деревьями решений
работать очень просто, они формируют легко интерпретируемое графическое
представление результатов и хорошо обрабатывают как дискретные, так и
непрерывные величины.
В таблице 1 показано, как можно представить данные, чтобы оценить отклик на
получение приглашения на конференцию по информационным технологиям. Хотя
приведенный набор данных невелик, все же придется затратить немало усилий на
то, чтобы визуально определить, имеется ли какой-то атрибут (столбец), по
которому можно предсказывать с большой долей вероятности, что его обладатель
примет приглашение на конференцию (пришлет отклик). И, если имеется такой
атрибут или набор атрибутов, то каков он. А теперь представьте себе, что надо
определить факторы, влияющие на вероятность отклика, для базы данных,
содержащей более 10 000 записей. Какой это атрибут - должность? Пол? Число
служащих или объем продаж? Увидеть прогнозирующие зависимости, учитывающие две
переменные, очень трудно. И практически невозможно увидеть комбинации
прогнозирующих зависимостей, лежащие в основе надежной прогнозирующей
классификации вероятности отклика.
На рисунке 1 показано дерево решений, раскрывающее прогнозирующую структуру
данных. Самым сильнодействующим фактором для прогнозирования отклика является
размер компании (измеряемый числом служащих). Общий коэффициент отклика (доля
ответивших на приглашение) составляет 40%. Из приглашенных сотрудников больших
компаний конференцию посетили 75%, в то время как только 27% сотрудников
небольших предприятий, получивших приглашение, откликнулись на него. Следовательно,
вероятность посещения конференции служащими больших компаний примерно в три
раза выше, чем сотрудниками малых предприятий. Однако такая характеристика
небольших компаний меняется, если исходить из объема продаж. Для двух случаев,
соответствующих объему продаж менее 1 млн. долларов, посещаемость составила
100%. Эти цифры показывают, что в рассматриваемом примере все сотрудники
компаний с годовым доходом менее 1 млн. долларов приняли участие в конференции.
Я привожу эти результаты лишь в качестве иллюстрации. В реальной жизни вы
никогда не станете делать выводы, основываясь на таком малом числе записей,
если только предварительно не было проведено обучение модели на достаточном
объеме данных, чтобы убедиться, что этот шаблон действительно существует в исследуемой
базе данных клиентов. Как следует из рисунка 1, дерево решений строится следующим образом. Сначала
берется весь набор данных, который обычно представляется исходной или корневой
вершиной, расположенной в верхней части рисунка. Затем определяются способы
разбиения на ветви всего множества записей или вариантов, соответствующих
корневому узлу. Ветви образуют дерево, перевернутое кроной вниз. Узлы на концах
ветвей обычно называются листьями. В реальных маркетинговых задачах обычно используется намного больше
атрибутов (столбцов) для описания каждого потенциального участника конференции,
и гораздо больше само количество предполагаемых участников. По мере роста
масштабов задачи трудоемкость получения прогнозирующих характеристик вручную
увеличивается очень быстро, так что возникает потребность в автоматической
обработке. Однако оценивать прогнозирующую способность множества атрибутов,
несмотря на применение специальных инструментов OLAP, по-прежнему трудно.
Получить представление о том, как используются средства исследования данных и
деревья решений, позволит рисунок 1. Общее количество откликнувшихся на
приглашение составляет 40%. Однако если рассматривать только малые компании с
большими объемами продаж ($1M+), то доля откликнувшихся снизится приблизительно
до 11%. Этот пример показывает, что можно измерить способность оценивать
падение коэффициента отклика по мере вовлечения в анализ большего количества
атрибутов. Затем полученный результат можно использовать для формирования
показателя прогнозирующих возможностей модели. Деревья решений хорошо
масштабируются при использовании атрибутов с множеством различных значений и
при большом количестве записей. Из-за этих особенностей деревья решений
оказываются чрезвычайно полезными при решении широкого спектра задач
прогнозирования и классификации. Кластерный анализ (сегментация).
Сегментация представляет собой процесс группирования отдельных случаев в
кластеры на основании того, что у этих случаев имеются сходные значения набора
атрибутов. Деревья решений также обнаруживают сегменты, но только исходя из
значения конкретной результирующей величины, например, наличия отклика на
приглашение принять участие в конференции. Так, значения, которые показаны в
виде числовых кодов или строковых значений одной ветви дерева решений образуют
кластер. Случаи, входящие в этот кластер (листья дерева решений), обладают
сходными значениями атрибута, формирующего ветвь дерева решений. К примеру, из
рисунка 1 видно, что клиенты, работающие на небольших предприятиях с высоким
уровнем доходов, образуют сегмент, характеризующийся самым низким значением
коэффициента отклика на приглашение по сравнению со всеми остальными сегментами
дерева решений. В дереве решений образуется ветвь, которая идентифицирует
сходство случаев в листовых кластерах и показывает, какой выбор был сделан
между двумя значениями выходной величины узла - в рассматриваемом примере между
значениями Есть отклик и Нет отклика. Если выходной переменной не
существует или если желательно посмотреть, как группируются отдельные
наблюдения с учетом сходства по нескольким выходным переменным, то следует
прибегнуть к методике кластерного анализа. При кластерном анализе экземпляры группируются в кластеры так, чтобы внутри
группы они обладали как можно более близкими значениями нескольких общих
атрибутов - таких как рост, вес и возраст - и как можно больше отличались по
этим параметрам от других кластеров, также образованных однородными
экземплярами. Все случаи, обладающие сходными структурами закупок или расходов, образуют
легко идентифицируемые сегменты рынка, которым можно сопоставить разные товары.
Другими словами, разбиение на кластеры может подсказать различные стратегии
обслуживания. Со временем сформировались разные методики решения задач кластерного
анализа. Одной из старейших методик кластерного анализа является итеративный
метод К средних. Применяя этот способ, пользователь назначает количество
кластеров (К). Для них вычисляются средние значения, служащие своего рода
центрами тяжести, вокруг которых будут группироваться отдельные экземпляры из
набора данных. Затем экземпляры перераспределяются по этим кластерам с учетом
степени близости. В Analysis Services применяется метод К средних с
рандомизацией (при котором первоначальное распределение по кластерам
выполняется случайным образом, а дальнейшее перераспределение производится в
кластер с ближайшим значением среднего). Внедрение OLE DB for Data Mining
Интерфейс OLE DB for Data Mining предназначен для применения как в качестве
интерфейса для исследования данных, так и в качестве средства управления
пользовательским интерфейсом (UI). Решение, предложенное Microsoft в SQL Server
2000, позволяет задействовать в качестве расширений этого интерфейса несколько
алгоритмов исследования данных. Кроме того, оно включает поддержку мастеров
исследования данных, последовательно проводящих пользователей по всем этапам
исследования. Расширение OLE DB for Data Mining позволяет подключиться к единой
взаимосвязанной информационной системе приложениям OLAP, пользовательским
приложениям, системным службам (таким как Commerce Server) и множеству
приложений и инструментальных средств производства независимых компаний.
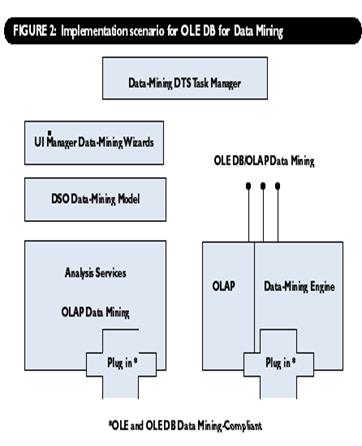
На рисунке 2 представлен общий сценарий внедрения OLE DB for Data Mining. Спецификации OLE DB for OLAP и OLE DB for Data Mining обеспечивают доступ к
службам исследования данных, соответствующим мастерам и приложениям независимых
производителей. Помимо спецификации OLE DB for Data Mining к числу ключевых
элементов среды DM относятся модель исследования данных DSO и процессор Data
Mining Engine, который включает как алгоритм деревьев принятия решений, так и
алгоритм кластерного анализа. Analysis Services и любые процессы компаний,
совместимые с OLE DB for Data Mining, могут подключаться к этой среде DM, чтобы
определять и создавать модели исследования данных, а также манипулировать ими.
Если для функционирования продуктов независимых производителей необходим
интерфейс OLE DB for Data Mining interface, то выполняемые этими продуктами
функции могут быть опубликованы, чтобы дать возможность применять их всем, кто
работает в этом окружении. На системном уровне специалисты Microsoft расширили модель DSO таким
образом, чтобы она поддерживала добавление нового типа объекта - DM-модели. Они
создали серверные компоненты, которые обеспечили встроенные возможности
применения как методов OLAP, так и DM. Эти возможности и определяют основные
особенности Analysis Services. На стороне клиента появились средства,
позволяющие клиентским частям OLAP и Data Mining Engine эксплуатировать
работающую на сервере службу Analysis Services. Клиентская часть предоставляет
полный доступ к обеим моделям, OLAP и DM, через спецификацию OLE DB for Data
Mining. Наконец, выпустив спецификацию OLE DB for Data Mining, корпорация Microsoft
предоставила независимым компаниям возможность применять интерфейсы СОМ,
входящие в состав OLE DB for Data Mining, чтобы и для средств исследования
данных обеспечить реализацию принципа plug-and-play. Эти возможности позволяют
добавлять новые функции исследования данных в те информационные среды, которые
удовлетворяют требованиям спецификации OLE DB for Data Mining. В настоящее
время такого рода расширения обеспечивают несколько независимых компаний,
выпускающих прикладные системы и инструментальные средства. В основном они
входят в альянс производителей хранилищ данных, Microsoft Data Warehousing
Alliance. Три компании, выпускающие продукты для исследования данных, являются
членами альянса: Angoss Software, DBMiner Technology и Megaputer Intelligence. Специалисты Microsoft спроектировали свою концепцию хранилищ данных, Data
Warehousing Framework, таким образом, чтобы она объединила потребности
бизнес-интеллекта и систем поддержки принятия решений. Эта концепция предлагает
для них единое основание, обеспечивающее высокий уровень быстродействия,
гибкость и невысокую стоимость. Члены альянса Data Warehousing Alliance
предлагают свои инструментальные и прикладные программные продукты для решения
задач расширения, преобразования и загрузки данных (Data Extension,
Transformation, and Loading, ETL), проведения аналитических работ, формирования
запросов и отчетов, а также для исследования данных. Более подробная информация
о концепции хранилищ данных (Data Warehousing Framework) и решениях для
бизнес-интеллекта содержится по адресу http://www.microsoft.com/industry/bi.
Подводя итоги
SQL Server 2000 оказал такое же заметное влияние на распространение знаний о
задачах и возможностях бизнес-интеллекта, как эволюция хранилищ данных, систем
поддержки принятия решений и средств OLAP. Методология OLAP, впервые введенная
корпорацией Microsoft в SQL Server 7.0, и методология исследования данных,
реализованная в SQL Server 2000, взаимно дополняют друг друга и образуют
синергичные средства анализа данных. Теперь для этих технологий применяются
общие форматы, общий пользовательский интерфейс и единая спецификация
интерфейса для приложений, которая используется в качестве руководства по
созданию, применению и развертыванию программных продуктов для анализа данных.
Этот значительный прогресс в разработке приведет к обобщению и унификации
представлений о формировании многомерных отчетов. Барри де Виль является разработчиком решений в области
исследования данных (Data Mining); создал дерево решений KnowledgeSEEKER. Барри
работает менеджером по контактам с клиентами (CRM) в SAS. В издательстве Digital Press готовится к
выходу в свет его книга "Microsoft Data Mining:
Integrating Business Intelligence for E-Commerce and Knowledge
Management". Его адрес электронной почты: barry_deville@yahoo.com. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
За содержание страницы отвечает Гончарова М.Н. © Кафедра СПиКБ, 2002-2017 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||