|
||||||||
|
||||||||

|
тЕДЕПЮРХБМШИ ДНЯРСО Й АЮГЮЛ ДЮММШУдЩБХД цХП, нРЙПШРШЕ ЯХЯРЕЛШ нПЦЮМХГЮЖХХ МЮЙЮОКХБЮЧР БЯЕ АНКЕЕ БМСЬХРЕКЭМШЕ НАЗЕЛШ ДЮММШУ ХГ ПЮЯРСЫЕЦН ВХЯКЮ ТСМЙЖХНМХПСЧЫХУ МЮ ПЮГКХВМШУ ОКЮРТНПЛЮУ ХЯРНВМХЙНБ, ЙЮЙ ЯРПСЙРСПХПНБЮММНИ, РЮЙ Х МЕЯРПСЙРСПХПНБЮММНИ ХМТНПЛЮЖХХ. нМХ УПЮМЪР ДЮММШЕ МЮ ОНВРНБШУ ЯЕПБЕПЮУ, МЮ Web-ЯЕПБЕПЮУ, Б ЩКЕЙРПНММШУ РЮАКХЖЮУ, Б ТЮИКЮУ ОПХКНФЕМХИ Х Б ТЮИКЮУ ЛЩИМТПЕИЛНБ. рЮЙ АЮМЙНБЯЙНЕ СВПЕФДЕМХЕ ЛНФЕР УПЮМХРЭ ЙЮЯЮЧЫХЕЯЪ НДМНЦН Х РНЦН ФЕ ЙКХЕМРЮ ЯБЕДЕМХЪ ЯПЮГС БН ЛМНЦХУ ХЯРНВМХЙЮУ. вЮЯРН АШБЮЕР, ВРН ДЮММШЕ ОПЕДЯРЮБКЕМШ Б ПЮГМШУ ТНПЛЮРЮУ ОНРНЛС, ВРН ЙНЛОЮМХХ ОНКЭГСЧРЯЪ МЕЯЙНКЭЙХЛХ ЯХЯРЕЛЮЛХ УПЮМЕМХЪ, ХКХ ОНРНЛС, ВРН НМХ ОПХНАПЕКХ ХКХ ЯКХКХЯЭ Я ДПСЦХЛХ ЙНЛОЮМХЪЛХоНХЯЙ МЕНАУНДХЛШУ ЯБЕДЕМХИ Б МЕЯЙНКЭЙХУ ХЯРНВМХЙЮУ ЛНФЕР АШРЭ ЯНОПЪФЕМ Я АНКЭЬХЛХ ЯКНФМНЯРЪЛХ Х ГМЮВХРЕКЭМШЛХ ГЮРПЮРЮЛХ БПЕЛЕМХ ≈ Б ОЕПБСЧ НВЕПЕДЭ ХГ-ГЮ РНЦН, ВРН Б УНДЕ ЙЮФДНИ НОЕПЮЖХХ ОНХЯЙЮ ГЮОПНЯШ ОНКЭГНБЮРЕКЕИ РПЮДХЖХНММН ЮДПЕЯСЧРЯЪ КХЬЭ НДМНЛС ХЯРНВМХЙС ДЮММШУ. яРНКЙМСБЬХЯЭ Я ЩРНИ ОПНАКЕЛНИ, МЕЙНРНПШЕ ОНЯРЮБЫХЙХ ПЮГПЮАНРЮКХ ПЕЬЕМХЪ, НЯМНБЮММШЕ МЮ РЕУМНКНЦХХ РЮЙ МЮГШБЮЕЛНЦН ╚ТЕДЕПЮРХБМНЦН╩ (federative) ДНЯРСОЮ Й МЕЯЙНКЭЙХЛ АЮГЮЛ ДЮММШУ. мЮГНБЕЛ РЮЙХЕ ОПНДСЙРШ, ЙЮЙ Liquid Data ЙНЛОЮМХХ BEA Systems, ОПНЦПЮЛЛМШИ ХМЯРПСЛЕМРЮПХИ IBM DB2 Information Integrator (DB2 II), ЯКЕДСЧЫЮЪ БЕПЯХЪ Microsoft SQL Server, ХГБЕЯРМЮЪ ОНД ПЮАНВХЛ МЮГБЮМХЕЛ Yukon, Х ясад Oracle 9i. я ОНЛНЫЭЧ ЩРХУ ЯПЕДЯРБ ОНКЭГНБЮРЕКХ ЛНЦСР НДМНБПЕЛЕММН НАПЮЫЮРЭЯЪ Я ГЮОПНЯЮЛХ ЯПЮГС Й МЕЯЙНКЭЙХЛ ПЮГМНПНДМШЛ ХЯРНВМХЙЮЛ ДЮММШУ. оНРПЕАМНЯРЭ Б РЕУМНКНЦХХ ТЕДЕПЮРХБМНЦН ДНЯРСОЮ Й АЮГЮЛ ДЮММШУ АСДЕР ОПНЪБКЪРЭЯЪ Б ОЕПБСЧ НВЕПЕДЭ ОПХ ЩЙЯОКСЮРЮЖХХ ЯХЯРЕЛ, ОПЕДМЮГМЮВЕММШУ ДКЪ СОПЮБКЕМХЪ Web-ЙНМРЕМРНЛ. йПНЛЕ РНЦН, ЙЮЙ СРБЕПФДЮЕР рЕД тПХДЛЮМ, ЮМЮКХРХЙ ЙНЛОЮМХХ Gartner, ЙНЛОЮМХХ АСДСР ПЕЮКХГНБШБЮРЭ ЩРС РЕУМНКНЦХЧ Б ЯХЯРЕЛЮУ СОПЮБКЕМХЪ НРМНЬЕМХЪЛХ Я ЙКХЕМРЮЛХ (customer relationship management, CRM), ЙНРНПШЕ, ЙЮЙ ОПЮБХКН, ПЮАНРЮЧР Я ДЮММШЛХ ХГ ЛМНЦХУ ХЯРНВМХЙНБ. бЕПНЪРМН, ОНЯРЮБЫХЙХ БНГЭЛСР ТЕДЕПЮРХБМШЕ РЕУМНКНЦХХ МЮ БННПСФЕМХЕ Б ЙЮВЕЯРБЕ ЯПЕДЯРБЮ ДКЪ ОНКСВЕМХЪ ОПЕХЛСЫЕЯРБ МЮ ПШМЙЕ ясад, НРКХВЮЧЫЕЛЯЪ ФЕЯРЙНИ ЙНМЙСПЕМЖХЕИ. рЕУМНКНЦХЪ ХГМСРПХ
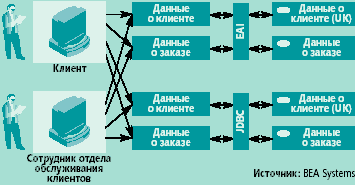
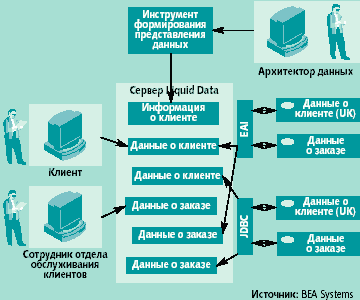
хМТНПЛЮЖХНММШЕ ЯХЯРЕЛШ РПЮДХЖХНММНИ ЮПУХРЕЙРСПШ (ПХЯ. 1) Б ЙЮФДШИ ЛНЛЕМР НАЕЯОЕВХБЮЧР ДНЯРСО КХЬЭ Й НДМНЛС ХЯРНВМХЙС ДЮММШУ. нАЗЪЯМЪЕРЯЪ ЩРН РЕЛ, ВРН ДН МЕДЮБМЕЦН БПЕЛЕМХ МЕ ЯСЫЕЯРБНБЮКН МХ СМХБЕПЯЮКЭМНЦН ЪГШЙЮ ДКЪ ДЮММШУ, МХ ЙЮВЕЯРБЕММШУ ЛЕРЮДЮММШУ. еЯКХ ОНКЭГНБЮРЕКХ ФЕКЮЧР ОНКСВХРЭ МЕНАУНДХЛШЕ ДЮММШЕ ХГ МЕЯЙНКЭЙХУ ХЯРНВМХЙНБ, НМХ ДНКФМШ ПЮЯОНКЮЦЮРЭ РНВМШЛХ ЛЕРЮДЮММШЛХ, НОХЯШБЮЧЫХЛХ УПЮМХЛШЕ ДЮММШЕ Б ТНПЛЮРЮУ, ДНЯРСОМШУ ДКЪ ВРЕМХЪ МЮ ПЮГКХВМШУ ОКЮРТНПЛЮУ. лЕФДС РЕЛ, ОПНЦПЮЛЛМШЕ Х ЮООЮПЮРМШЕ ЯПЕДЯРБЮ МЕ НРКХВЮКХЯЭ МХ ДНЯРЮРНВМНИ ЛНЫМНЯРЭЧ, МХ ТСМЙЖХНМЮКЭМНЯРЭЧ, МЕНАУНДХЛНИ ДКЪ НЯСЫЕЯРБКЕМХЪ ДНЯРСОЮ Й ПЮЯОПЕДЕКЕММШЛ ДЮММШЛ. пЮМЭЬЕ ПЮГПЮАНРВХЙХ БПСВМСЧ ЯНГДЮБЮКХ ЮДЮОРЕПШ ДКЪ ПЮАНРШ Я ОНКСВЕММШЛХ ХГ МЕЯЙНКЭЙХУ ХЯРНВМХЙНБ ДЮММШЛХ, ХЯОНКЭГСЪ ОПХ ЩРНЛ API ЯННРБЕРЯРБСЧЫХУ ХЯРНВМХЙНБ. нДМЮЙН БПСВМСЧ ЯНГДЮММШЕ ЮДЮОРЕПШ МЕ ЯОНЯНАМШ ЮБРНЛЮРХВЕЯЙХ ОНДЯРПЮХБЮРЭЯЪ ОНД НАМНБКЪЕЛШЕ БЕПЯХХ API. жЕМРПЮКХГНБЮММШИ ОНДУНДжЕМРПЮКХГНБЮММШИ ОНДУНД Й ХГБКЕВЕМХЧ ДЮММШУ ХГ ПЮГКХВМШУ ХЯРНВМХЙНБ, ЙЮЙ ОПЮБХКН, ОПЕДОНКЮЦЮЕР ДСАКХПНБЮМХЕ Х ОНЯКЕДСЧЫХИ ЯАНП ЯЙНОХПНБЮММШУ ДЮММШУ Б НДМС АЮГС (ХКХ НВЕМЭ МЕАНКЭЬНЕ ХУ ВХЯКН). гЮРЕЛ ОНКЭГНБЮРЕКХ НАПЮЫЮЧРЯЪ Й ЩРХЛ ЮЦПЕЦХПНБЮММШЛ АЮГЮЛ ДЮММШУ, ЙНРНПШЕ ХМНЦДЮ МЮГШБЮЧР УПЮМХКХЫЮЛХ. йНЦДЮ ДЮММШЕ ЯНАПЮМШ Б НДМНЛ ХЯРНВМХЙЕ, ОНКЭГНБЮРЕКХ ЛНЦСР АШЯРПЕЕ ОНКСВХРЭ РПЕАСЕЛСЧ ХМТНПЛЮЖХЧ, Ю ЯХЯРЕЛЮ ЛНФЕР Я АНКЭЬЕИ КЕЦЙНЯРЭЧ, ВЕЛ Б ЯКСВЮЕ, ЕЯКХ АШ БЕЯЭ ЛЮРЕПХЮК АШК ПЮГАПНЯЮМ ОН ПЮГКХВМШЛ ЯХЯРЕЛЮЛ, МНПЛЮКХГНБЮРЭ ДЮММШЕ Х БШОНКМХРЭ ДПСЦХЕ НОЕПЮЖХХ ОН ХУ НАПЮАНРЙЕ. нДМЮЙН ДКЪ ЯАНПЮ ХМТНПЛЮЖХХ Б ЖЕМРПЮКХГНБЮММШИ ХЯРНВМХЙ РПЕАСЕРЯЪ, ВРНАШ ДЮММШЕ, ЙНРНПШЕ ВЮЯРН УПЮМЪРЯЪ Б ПЮГКХВМШУ ТНПЛЮРЮУ, АШКХ ОПХБЕДЕМШ Й НДМНЛС, Ю Б УНДЕ ЩРНЦН ОПНЖЕЯЯЮ, БНГЛНФМН ОНЪБКЕМХЕ НЬХАНЙ. йПНЛЕ РНЦН, УПЮМХКХЫЮЛ ДЮММШУ ЛНФЕР НЙЮГЮРЭЯЪ ЯКНФМН БГЮХЛНДЕИЯРБНБЮРЭ Я МНБШЛХ ХЯРНВМХЙЮЛХ ДЮММШУ Б МЕГМЮЙНЛШУ ТНПЛЮРЮУ. мЮЙНМЕЖ, РН НАЯРНЪРЕКЭЯРБН, ВРН ДЮММШЕ МСФМН ДСАКХПНБЮРЭ Х ПЮАНРЮРЭ Я МЕЯЙНКЭЙХЛХ ХУ ЙНОХЪЛХ, ОПХБНДХР Й ОНБШЬЕМХЧ ХГДЕПФЕЙ. тЕДЕПЮРХБМШИ ОНДУНДтЕДЕПЮРХБМШИ ОНДУНД (ЕЦН ПЕЮКХГЮЖХЧ ЯПЕДЯРБЮЛХ Liquid Data ХККЧЯРПХПСЕР ПХЯ. 2) ОПЕДОНКЮЦЮЕР ДНЯРСО Й ДЮММШЛ, МЮУНДЪЫХЛЯЪ МЕОНЯПЕДЯРБЕММН Б ПЮГМНПНДМШУ ХЯРНВМХЙЮУ, Х ЯНГДЮМХЕ ЕДХМНЦН БХПРСЮКЭМНЦН УПЮМХКХЫЮ. пЮГПЮАНРВХЙХ ЛНЦСР ОХЯЮРЭ БЯЕ ЯБНХ ГЮОПНЯШ Й ТЕДЕПЮРХБМНИ ЯХЯРЕЛЕ ДЮММШУ, ХЦПЮЧЫЕИ ПНКЭ ОНЯПЕДМХЙЮ, ПНКЭ ЙНРНПНЦН, Б ЯСЫМНЯРХ, ЯНЯРНХР Б РНЛ, ВРНАШ ЮАЯРПЮЦХПНБЮРЭЯЪ НР ЯНЕДХМЕМХИ Я ПЮГКХВМШЛХ ЯЕПБЕПМШЛХ ХЯРНВМХЙЮЛХ ДЮММШУ.
нДМЮЙН, ЙЮЙ ОНЪЯМЪЕР тПХДЛЮМ ХГ Gartner, ОПНЖЕЯЯ ЯАНПЮ ДЮММШУ ХГ ПЮГКХВМШУ ХЯРНВМХЙНБ ЯНГДЮЕР ДНОНКМХРЕКЭМСЧ МЮЦПСГЙС МЮ ЯХЯРЕЛС. й РНЛС ФЕ НАПЮАНРЙЮ ╚МЮ КЕРС╩ ПЮЯОПЕДЕКЕММШУ ГЮОПНЯНБ, НАПЮЫЕММШУ Й ПЮГКХВМШЛ ХЯРНВМХЙЮЛ ДЮММШУ, ОН ЕЦН ЯКНБЮЛ, ОПЕДОНКЮЦЮЕР ОЕПЕЛЕЫЕМХЕ ОН ЯЕРХ ГМЮВХРЕКЭМШУ НАЗЕЛНБ ДЮММШУ, ВРН ЛНФЕР ЯСЫЕЯРБЕММН ЯМХГХРЭ ЕЕ ОПНОСЯЙМСЧ ЯОНЯНАМНЯРЭ. мЮЙНМЕЖ, Б ЯКСВЮЕ ХЯОНКЭГНБЮМХЪ ТЕДЕПЮРХБМНЦН ОНДУНДЮ ОПХ БШОНКМЕМХХ МНПЛЮКХГЮЖХХ Х ДПСЦХУ НОЕПЮЖХИ ОН НАПЮАНРЙЕ ДЮММШУ БНГМХЙЮЕР АНКЭЬЕ ЯКНФМНЯРЕИ. б ОЕПХНД Я 1998-ЦН ОН 2001 ЦНД ПЮГПЮАНРЙНИ Х ОПНДБХФЕМХЕЛ ТЕДЕПЮРХБМШУ РЕУМНКНЦХИ АЮГ ДЮММШУ ОШРЮКХЯЭ ГЮМХЛЮРЭЯЪ МЕЯЙНКЭЙН ЙНЛОЮМХИ. мН ВЮЯРН ХУ ЯХЯРЕЛШ НЙЮГШБЮКХЯЭ ЯКХЬЙНЛ ЯКНФМШЛХ, Ю ПЮГПЮАНРЮММШЕ ЯПЕДЯРБЮ НАПЮАНРЙХ ПЮЯОПЕДЕКЕММШУ ГЮОПНЯНБ ОКНУН ЯОПЮБКЪКХЯЭ ЯН ЯБНХЛХ ГЮДЮВЮЛХ. яЕЦНДМЪ Б ПЮЛЙЮУ ТЕДЕПЮРХБМНИ РЕУМНКНЦХХ ДНЯРСОЮ Й АЮГЮЛ ДЮММШУ ЯКНФХКНЯЭ ДБЮ НЯМНБМШУ ОНДУНДЮ. яЕПБЕПМШИ ОНДУНД ОПЕДОНКЮЦЮЕР ТХГХВЕЯЙНЕ ЯНГДЮМХЕ ТЕДЕПЮРХБМНЦН ОСРХ ДКЪ НДМНБПЕЛЕММНЦН ДНЯРСОЮ Й ДЮММШУ ХГ МЕЯЙНКЭЙХУ ПЮГМНПНДМШУ ХЯРНВМХЙНБ. оНЯРЮБЫХЙХ ЛНДЕПМХГХПСЧР ЯЕПБЕПШ АЮГ ДЮММШУ РЮЙ, ВРНАШ НМХ Я АНКЭЬЕИ ЩТТЕЙРХБМНЯРЭЧ БГЮХЛНДЕИЯРБНБЮКХ Я ДПСЦХЛХ ЯЕПБЕПЮЛХ. оНДУНД МЮ АЮГЕ ОПНЦПЮЛЛМНЦН НАЕЯОЕВЕМХЪ ОПНЛЕФСРНВМНЦН ЯКНЪ ОПЕДОНКЮЦЮЕР СЯРЮМНБКЕМХЕ ЙЮМЮКНБ ЯБЪГХ ЛЕФДС ОНКЭГНБЮРЕКЪЛХ Х ХЯРНВМХЙЮЛХ ДЮММШУ ОПНЦПЮЛЛМШЛ ОСРЕЛ. дНЯРСО НДМХУ ЯЕПБЕПНБ Й ДПСЦХЛ НЯСЫЕЯРБКЪЕРЯЪ МЕ ВЕПЕГ ЮООЮПЮРМШЕ ЙНЛОНМЕМРШ, Ю Я ОНЛНЫЭЧ ОПНЦПЮЛЛМШУ ЯПЕДЯРБ. мНБШЕ РЕУМНКНЦХХбНГЛНФМНЯРЭ НДМНБПЕЛЕММН МЮОПЮБКЪРЭ ГЮОПНЯШ МЕЯЙНКЭЙХЛ ХЯРНВМХЙЮЛ, ЯНДЕПФЮЫХЛ ПЮГМНПНДМШЕ ДЮММШЕ, БНГМХЙКЮ АКЮЦНДЮПЪ МЕЯЙНКЭЙХЛ РЕУМНКНЦХВЕЯЙХЛ ПЕЬЕМХЪЛ. рЮЙ, ОНБШЬЕМХЕ ЩТТЕЙРХБМНЯРХ НОРХЛХГЮРНПНБ ГЮОПНЯНБ, ОПНЦПЮЛЛ, ЙНРНПШЕ Я ОНЛНЫЭЧ ЯХЯРЕЛШ ОПЮБХК НЯСЫЕЯРБКЪЧР РНМЙСЧ ОНДЯРПНИЙС БШОНКМЕМХЪ ГЮОПНЯНБ, ЯРЮКН ЯКЕДЯРБХЕЛ ОПХЛЕМЕМХЪ АНКЕЕ ЯНБЕПЬЕММШУ ЮКЦНПХРЛНБ. я ДПСЦНИ ЯРНПНМШ, ОНБШЯХКНЯЭ АШЯРПНДЕИЯРБХЕ ЖЕМРПЮКЭМШУ ОПНЖЕЯЯНПНБ Х ФЕЯРЙХУ ДХЯЙНБ, ВРН ОПХБЕКН Й ПНЯРС ОПНХГБНДХРЕКЭМНЯРХ ЯХЯРЕЛ ОНХЯЙЮ. рЕУМНКНЦХЪ ТЕДЕПЮРХБМНЦН ДНЯРСОЮ Й АЮГЮЛ ДЮММШУ ОНГБНКЪЕР БГЮХЛНДЕИЯРБНБЮРЭ (Б РНИ ХКХ ХМНИ ЯРЕОЕМХ) Я ДЮММШЛХ, МЮОХЯЮММШЛХ ОПЮЙРХВЕЯЙХ МЮ КЧАНЛ ЪГШЙЕ, НДМЮЙН ЯБНХЛ ЯСЫЕЯРБНБЮМХЕЛ НМЮ БН ЛМНЦНЛ НАЪГЮМЮ ЪГШЙС XML. хЯОНКЭГСЕЛШЕ Б ЪГШЙЕ XML РЕЦХ ОПЕДЯРЮБКЪЧР ЯЕЛЮМРХЙС ДЮММШУ, ЙНРНПЮЪ ЛНФЕР АШРЭ ПЮЯОНГМЮМЮ ПЮГМНПНДМШЛХ ЯХЯРЕЛЮЛХ. рЮЙХЛ НАПЮГНЛ, XML НАКЕЦВЮЕР БШОНКМЕМХЕ ГЮОПНЯНБ МЮ ОНКСВЕМХЕ ХМТНПЛЮЖХХ, УПЮМЪЫЕИЯЪ МЮ ПЮГКХВМШУ ОКЮРТНПЛЮУ Б ПЮГКХВМШУ ЯРПСЙРСПЮУ ДЮММШУ. XML ОНЛНЦЮЕР ЯХЯРЕЛЕ ПЮЯЬХТПНБШБЮРЭ ДЮММШЕ ХГ ПЮГМНПНДМШУ ХЯРНВМХЙНБ, Ю ЯЕРХ Х НЯМЮЫЕММШЕ ЯПЕДЯРБЮЛХ ЛМНЦНОНРНЙНБНИ НАПЮАНРЙХ НОЕПЮЖХНММШЕ ЯХЯРЕЛШ НДМНБПЕЛЕММН НАПЮАЮРШБЮЧР ГЮОПНЯШ ОНКЭГНБЮРЕКЪ МЮ ОНКСВЕМХЕ ДЮММШУ ХГ МЕЯЙНКЭЙХУ УПЮМХКХЫ. бЮФМНИ РЕУМНКНЦХЕИ, НАЕЯОЕВХБЮЧЫЕИ ПЕЮКХГЮЖХЧ НАЗЕДХМЕММНЦН ДНЯРСОЮ Й АЮГЮЛ ДЮММШУ, НАЕЫЮЕР ЯРЮРЭ ЪГШЙ XQuery. щРНР ЪГШЙ ОНГБНКЪЕР ОНКЭГНБЮРЕКЪЛ ТНПЛСКХПНБЮРЭ ╚ХМРЕККЕЙРСЮКЭМШЕ╩ ГЮОПНЯШ МЮ ХМТНПЛЮЖХЧ, УПЮМХЛСЧ Б ПЮГКХВМШУ ХЯРНВМХЙЮУ, НАЛЕМХБЮЕЛСЧ ЛЕФДС ЩРХЛХ ХЯРНВМХЙЮЛХ Х ОПЕДЯРЮБКЪЕЛСЧ ХГ МХУ Я ОНЛНЫЭЧ XML. аЕГ НЯНАНЦН ЪГШЙЮ, ОПЕДМЮГМЮВЕММНЦН ДКЪ ЯНЯРЮБКЕМХЪ ГЮОПНЯНБ Й ТЮИКЮЛ XML РПСДМН НАНИРХЯЭ, ОНЯЙНКЭЙС ЯНДЕПФЮЫХЕЯЪ Б РЮЙХУ ТЮИКЮУ ДЮММШЕ НАПЮГСЧР ХЕПЮПУХВЕЯЙХЕ ЯРПСЙРСПШ Х, ГМЮВХР, МЕ БОХЯШБЮЧРЯЪ Б ПЕКЪЖХНММСЧ ЛНДЕКЭ ДЮММШУ, Б ПЮЛЙЮУ ЙНРНПНИ НАШВМН Х ХЯОНКЭГСЕРЯЪ ЪГШЙ SQL. мНБШИ ЪГШЙ ДКЪ ЯНБПЕЛЕММШУ РЕУМНКНЦХИ СОПЮБКЕМХЪ АЮГЮЛХ ДЮММШУ МСФЕМ ЕЫЕ Х ОНРНЛС, ВРН ЪГШЙ SQL АШК ПЮГПЮАНРЮМ Б ЙНМЖЕ 70-У ЦНДНБ, Б ОЕПХНД, ЙНЦДЮ МЕ АШКН МХ Internet, МХ XML. оПНДСЙРШ, ПЕЮКХГСЧЫХЕ РЕУМНКНЦХЧ ТЕДЕПЮРХБМНЦН ДНЯРСОЮBEA Liquid DataйНЛОЮМХЪ BEA Systems ПЮГПЮАНРЮКЮ ЯХЯРЕЛС Liquid Data ДКЪ ЯБНЕЦН ЯЕПБЕПЮ ОПХКНФЕМХИ WebLogic Enterprise Platform. оН ЯКНБЮЛ щДФЕЪ оЮРЕКЮ, БХЖЕ-ОПЕГХДЕМРЮ ЙНЛОЮМХХ Х ЦЕМЕПЮКЭМНЦН ЛЕМЕДФЕПЮ ОН Liquid Data, ЩРНР ОПНДСЙР, Б НЯМНБС ЙНРНПНЦН ОНКНФЕМН ЯБЪГСЧЫЕЕ он, БШЯРСОЮЕР Б ЙЮВЕЯРБЕ ХМРЕПТЕИЯЮ ЛЕФДС ОНКЭГНБЮРЕКЕЛ Х ПЮЯОПЕДЕКЕММШЛХ ЯЕПБЕПЮЛХ. дКЪ ПЮЯОНГМЮБЮМХЪ ЛНЫМШУ ЛЕРЮДЮММШУ Х ОНЯКЕДСЧЫЕЦН ХУ ХЯОНКЭГНБЮМХЪ Я ЖЕКЭЧ ХГБКЕВЕМХЪ ДЮММШУ ХГ МЕЯЙНКЭЙХУ ХЯРНВМХЙНБ, ДЮММЮЪ РЕУМНКНЦХЪ ОПЕДСЯЛЮРПХБЮЕР ОПХЛЕМЕМХЕ ЪГШЙЮ XML Б ЯНВЕРЮМХХ Я Web-ЯКСФАЮЛХ. дЮММШЕ ХГ ПЮГКХВМШУ АЮГ ДЮММШУ ЮБРНЛЮРХВЕЯЙХ ОПХБНДЪРЯЪ Й ЯРЮМДЮПРС XML. IBM DB2 Information IntegratorпЮГПЮАНРЮММШИ ЙНПОНПЮЖХЕИ IBM ОПНДСЙР DB2 II ОПЕДЯРЮБКЪЕР ЯНАНИ ТЕДЕПЮРХБМШИ ЯЕПБЕП ДКЪ ХМРЕЦПЮЖХХ ДЮММШУ. яХЯРЕЛЮ НОПЮЬХБЮЕР ХЯРНВМХЙХ ДЮММШУ ХГ ХУ ЛЕЯР ПЮЯОНКНФЕМХЪ Х ГЮРЕЛ Я ОНЛНЫЭЧ СОПЮБКЪЧЫХУ АЮГЮЛХ ДЮММШУ ЯЕПБЕПНБ ЙНМЯНКХДХПСЕР ОНКСВЕММШЕ ПЕГСКЭРЮРШ. тСМЙЖХНМХПНБЮМХЕ ЯХЯРЕЛШ НРВЮЯРХ НАЕЯОЕВХБЮЕРЯЪ РЕЛ, ВРН ПЮГПЮАНРЮММЮЪ ЙНЛОЮМХЕИ ОКЮРТНПЛЮ DB2, ЙНРНПЮЪ СФЕ ЯНБЛЕЯРХЛЮ Я ЪГШЙНЛ SQL, НЯМЮЫЮЕРЯЪ ХМРЕПТЕИЯНЛ XQuery. дКЪ БГЮХЛНДЕИЯРБХЪ Я ХЯРНВМХЙЮЛХ ДЮММШУ, ЯНГДЮММШУ ДПСЦХЛХ ОПНХГБНДХРЕКЪЛХ, Б ЯХЯРЕЛЕ DB2 II ХЯОНКЭГСЧРЯЪ ЯОЕЖХЮКЭМШЕ ╚НАЕПРНВМШЕ╩ ОПНЦПЮЛЛШ. Microsoft YukonдН ЙНМЖЮ 2003 ЦНДЮ Microsoft ОКЮМХПСЕР БШОСЯРХРЭ Б ЯБЕР АЕРЮ-БЕПЯХЧ Yukon. щРН НДХМ ХГ БЮПХЮМРНБ ПЮГПЮАНРЮММНИ Б ЙНЛОЮМХХ ясад SQL Server, Б ЙНРНПНЛ, ОНЛХЛН ОПНВЕЦН, АСДЕР НАКЕЦВЕМЮ НАПЮАНРЙЮ ДЮММШУ, ОПЕДЯРЮБКЕММШУ Б ПЮГМШУ ТНПЛЮРЮУ Х ОНКСВЕММШУ ХГ ПЮГМШУ ХЯРНВМХЙНБ. б ОЮЙЕРЕ Yukon ГЮХЛЯРБНБЮММШЕ ХГ SQL Server ЯПЕДЯРБЮ ДКЪ ПЮАНРШ Я XML АСДСР ДНОНКМЕМШ ХМРЕПТЕИЯНЛ XQuery, ВРН ДЮЯР БНГЛНФМНЯРЭ ХЯОНКЭГНБЮРЭ ЙЮЙ SQL-, РЮЙ Х XQuery-ГЮОПНЯШ. йПНЛЕ РНЦН, Б ХГДЕКХХ Yukon АСДСР ПЕЮКХГНБЮМШ Х НАЗЕДХМЕММЮЪ, Х ЖЕМРПЮКХГНБЮММЮЪ ЛНДЕКХ ДНЯРСОЮ Й ДЮММШЛ. Microsoft ОКЮМХПСЕР МЮВЮРЭ БШОСЯЙ Yukon НДМНБПЕЛЕММН Я БШОСЯЙНЛ БЕПЯХХ ня Windows, ХЛЕЧЫЕИ ПЮАНВЕЕ МЮГБЮМХЕ Longhorn. Oracle 9iяЮМДХОЮМ аЮМЕПДФХ, ЙСПХПСЧЫХИ БНОПНЯШ СОПЮБКЕМХЪ ОПНДСЙРЮЛХ Б НРДЕКЕ ЯЕПБЕПМШУ РЕУМНКНЦХИ Oracle, СРБЕПФДЮЕР, ВРН Б Oracle 9i ПЕЮКХГНБЮМШ НАЮ ОНДУНДЮ Й НПЦЮМХГЮЖХХ ТЕДЕПЮРХБМНЦН ДНЯРСОЮ Й ДЮММШЛ ХГ МЕЯЙНКЭЙХУ ПЮГМНПНДМШУ ХЯРНВМХЙНБ. оКЮРТНПЛЮ Oracle 9i ОПЕДМЮГМЮВЕМЮ ОПЕФДЕ БЯЕЦН ДКЪ БГЮХЛНДЕИЯРБХЪ Я УПЮМХКХЫЮЛХ ДЮММШУ Б ЯННРБЕРЯРБХХ Я ЖЕМРПЮКХГНБЮММНИ ЛНДЕКЭЧ. нДМЮЙН, ЙЮЙ ОНЪЯМЪЕР пНАЕПР рНСЛ , ЛЕМЕДФЕП ОН ОПНДСЙРЮЛ ЦПСООШ ПЮГПЮАНРЙХ ПЮЯОПЕДЕКЕММШУ АЮГ ДЮММШУ Oracle, ╚ЕЯКХ БЮЯ АНКЭЬЕ СЯРПЮХБЮЕР НАЗЕДХМЕММШИ ОНДУНД, ЛНФЕРЕ БНЯОНКЭГНБЮРЭЯЪ ЯПЕДЯРБНЛ, ЙНРНПНЕ ЛШ ХЛЕМСЕЛ Distributed SQL╩. щРЮ ТСМЙЖХЪ ХМРЕЦПХПСЕР МЕЯЙНКЭЙН УПЮМХКХЫ ДЮММШУ. йПНЛЕ РНЦН, Oracle 9i ОПЕДОНКЮЦЮЕР ХЯОНКЭГНБЮМХЕ ЯКНБЮПЪ ДЮММШУ ДКЪ НОПНЯЮ СДЮКЕММШУ АЮГ ДЮММШУ Н РЮЙХУ, Й ОПХЛЕПС, ЯБЕДЕМХЪУ, ЙЮЙ ХЛЕМЮ ХУ РЮАКХЖ Х ЯРНКАЖНБ. оНЯПЕДЯРБНЛ ЩРНЦН ТНПЛХПСЕРЯЪ ОПЕДЯРЮБКЕМХЕ Н ОНКСВЮЕЛШУ ДЮММШУ. б ОПНДСЙРЕ ПЕЮКХГНБЮМЮ РЕУМНКНЦХЪ Oracle Streams, НАЕЯОЕВХБЮЧЫЮЪ ПЕЦХЯРПЮЖХЧ ХГЛЕМЕМХИ Б ЯНДЕПФХЛНЛ СДЮКЕММШУ АЮГ ДЮММШУ Х УПЮМЕМХЕ ХУ Б НВЕПЕДЪУ. оНГДМЕЕ ОНКЭГНБЮРЕКХ ЛНЦСР НРПЮФЮРЭ ЩРХ ХГЛЕМЕМХЪ Б ЯБНХУ ЯХЯРЕЛЮУ; ЩРЮ ОПНЖЕДСПЮ ЦЮПЮМРХПСЕР, ВРН Б ПЮЯОНПЪФЕМХЕ ОНКЭГНБЮРЕКЕИ ОНОЮДЮЧР ЯЮЛШЕ ОНЯКЕДМХЕ БЕПЯХХ ДЮММШУ ХГ ПЮГКХВМШУ ХЯРНВМХЙНБ. оПХ ХЯОНКЭГНБЮМХХ РЕУМНКНЦХИ ТЕДЕПЮРХБМНЦН ДНЯРСОЮ Й АЮГЮЛ ДЮММШУ ХЛЕЧР ЛЕЯРН ДНЯРЮРНВМН ХМРЕМЯХБМШЕ НАЛЕМШ ЛЕФДС ОНКЭГНБЮРЕКЪЛХ Х ХЯРНВМХЙЮЛХ ДЮММШУ, ОНЩРНЛС Б ЯЕРЪУ НРЛЕВЮЧРЯЪ ГЮДЕПФЙХ Х МЕОПНХГБНДХРЕКЭМШЕ ГЮРПЮРШ ПЕЯСПЯНБ. йПНЛЕ РНЦН, МЮ ЯЕПБЕПШ БНГКЮЦЮЕРЯЪ АПЕЛЪ ОНКСВЕМХЪ Х НАПЮАНРЙХ ГЮОПНЯНБ; ЯЕПБЕПШ ДНКФМШ ОПЕНАПЮГНБШБЮРЭ, НВХЫЮРЭ Х НОРХЛХГХПНБЮРЭ ДЮММШЕ. бЯЕ ЩРХ ТЮЙРНПШ ЯМХФЮЧР ОПНХГБНДХРЕКЭМНЯРЭ ЯХЯРЕЛШ. еЯКХ МЮ ОПНРЪФЕМХХ АКХФЮИЬХУ ОЪРХ КЕР ЯОПНЯ МЮ РЕУМНКНЦХХ ТЕДЕПЮРХБМНЦН ДНЯРСОЮ Й АЮГЮЛ ДЮММШУ БНГПЮЯРЕР, ЩРН АСДЕР ХЛЕРЭ ОНКНФХРЕКЭМНЕ БНГДЕИЯРБХЕ МЮ ПШМНЙ ╚ОКНЯЙХУ╩ АЮГ ДЮММШУ. ю РНР ТЮЙР, ВРН Б W3C ГЮМХЛЮЧРЯЪ ПЮГПЮАНРЙНИ ЯРЮМДЮПРЮ XQuery, ЛНФЕР ЯОНЯНАЯРБНБЮРЭ ОНЪБКЕМХЧ МЮ ПШМЙЕ МНБШУ ОНЯРЮБЫХЙНБ ЯПЕДЯРБ ТЕДЕПЮРХБМНЦН ДНЯРСОЮ Й АЮГЮЛ ДЮММШУ. еЯРЭ НЯМНБЮМХЪ ОНКЮЦЮРЭ, ВРН ОН ЛЕПЕ РНЦН, ЙЮЙ ОНБШЬЮЕРЯЪ ЩТТЕЙРХБМНЯРЭ ОПНЖЕЯЯНПНБ Х ЮКЦНПХРЛНБ ЙЩЬХПНБЮМХЪ, АСДЕР ПЮЯРХ Х ЩТТЕЙРХБМНЯРЭ РЕУМНКНЦХИ ТЕДЕПЮРХБМНЦН ДНЯРСОЮ Й АЮГЮЛ ДЮММШУ, НРЛЕРХК тХКХОО пЮЯЯНЛ, ЮМЮКХРХЙ ЙНЛОЮМХХ Giga Information Group. яРХБЕМ н▓цПЕИДХ, ЮМЮКХРХЙ ГЮМХЛЮЧЫЕИЯЪ ХЯЯКЕДНБЮМХЪЛХ ПШМЙЮ ЙНЛОЮМХХ RedMonk, ОНКЮЦЮЕР, ВРН АСДСЫЕЕ ГЮ РЕУМНКНЦХЪЛХ ТЕДЕПЮРХБМНЦН ДНЯРСОЮ Й АЮГЮЛ ДЮММШУ. ╚оСЯРЭ ПЮГМШЕ ОНЯРЮБЫХЙХ ОПЕДКЮЦЮЧР ПЮГКХВМШЕ ПЕЬЕМХЪ ОПНАКЕЛШ, ≈ НРЛЕРХК НМ, ≈ МН БЯЕ ДЕКН Б РНЛ, ВРН РЕУМХВЕЯЙХЕ ЯПЕДЯРБЮ Б ДЮММНИ ЯТЕПЕ МЮЙНМЕЖ-РН БШЬКХ МЮ СПНБЕМЭ ОНРПЕАМНЯРЕИ, Ю ГМЮВХР, ВРН ОПХЬКН БПЕЛЪ ЯПЕДЯРБ СОПЮБКЕМХЪ ТЕДЕПЮРХБМЛХ ДЮММШЛХ. оН ЛЕПЕ РНЦН ЙЮЙ ОПЕДОПХЪРХЪ АСДСР ОПНЪБКЪРЭ БЯЕ АНКЭЬХИ ХМРЕПЕЯ Й ХМТНПЛЮЖХХ, МЮУНДЪЫЕИЯЪ МЮ ОЕПХТЕПХХ ЦКЮБМНЦН ОНКЪ ДЕЪРЕКЭМНЯРХ ОПЕДОПХЪРХЪ, ЯОПНЯ МЮ ЩРХ ХГДЕКХЪ АСДЕР ПЮЯРХ╩. оНОШРЙХ ПЕЮКХГНБЮРЭ ТЕДЕПЮРХБМШИ ОНДУНД ОПЕДОПХМХЛЮКХЯЭ Х ПЮМЭЬЕ, МН АЕГ НЯНАНЦН СЯОЕУЮ. б МЕЙНРНПШУ ЯКСВЮЪУ ПЮГПЮАНРВХЙЮЛ СДЮБЮКНЯЭ ОНКСВЮРЭ ДНЯРСО Й АНКЕЕ ВЕЛ НДМНЛС УПЮМХКХЫС ДЮММШУ, НДМЮЙН ГЮДЮВЮ МЮДКЕФЮЫЕИ ХМРЕЦПЮЖХХ Я ЛМНЦХЛХ ХЯРНВМХЙЮЛХ ДН МЕДЮБМХУ ОНП НЯРЮБЮКЮЯЭ МЕПЮГПЕЬЕММНИ. *** тЕДЕПЮРХБМЮЪ РЕУМНКНЦХЪ, ЙЮЙ ОПЮБХКН, НАУНДХРЯЪ ДЕЬЕБКЕ, ОНГБНКЪЕР БШОНКМЪРЭ ГЮДЮВС АШЯРПЕЕ Х ОНПНФДЮЕР ЛЕМЭЬЕ НЬХАНЙ, ОНЯЙНКЭЙС ДЮММШЕ НЯРЮЧРЯЪ МЮ ЛЕЯРЮУ ЯБНЕЦН ОНЯРНЪММНЦН УПЮМЕМХЪ. йПНЛЕ РНЦН, Я ОНЛНЫЭЧ ЩРНИ ЛЕРНДХЙХ ЛНФМН Я КЕЦЙНЯРЭЧ НАПЮЫЮРЭЯЪ Й МНБШЛ ХЯРНВМХЙЮЛ ДЮММШУ.дЩБХД цХП (d@geercom.com) ≈ МЕГЮБХЯХЛШИ ЮБРНП, ЯОЕЖХЮКХГХПСЧЫХИЯЪ МЮ ОПНАКЕЛЮУ РЕУМНКНЦХХ. David Geer, Federated Approach Expands Database-Access Technology. IEEE Computer, May 2003. IEEE Computer Society, 2003, All rights reserved. Reprinted with permission. |
||||||||||||||
|
За содержание страницы отвечает Гончарова М.Н. © Кафедра СПиКБ, 2002-2017 |
|||||||||||||||