Обзор алгоритмов сжатия без потерь
Алгоритм LZM
LZM представляет собой комбинацию алгоритмов LZSS и RLE. Он рассчитан на сжатие блоков информации длиной до 8 Кб. Для работы ему необходим внутренний буфер размером 8 Кб. Основной стратегией разработки алгоритма было обеспечить приемлемое сжатие при максимальном быстродействии и минимальных затратах памяти.
Коды LZM
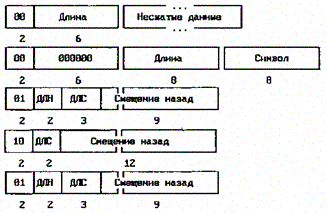
Как и любой другой алгоритм сжатия без потерь, кодер LZM конвертирует входное сообщение в набор кодов, которые впоследствии могут быть однозначно декодированы. Каждый код LZM начинается с маркера, за которым могут следовать несжатые данные. Форматы маркеров LZM приведены на рисунке.
Маркеры алгоритма LZM. Условные обозначения: ДЛН — длина несжатого фрагмента, следующего сразу за маркером, ДЛС — длина совпадения.
Как видно из таблицы, каждый маркер имеет уникальный 2-битовый префикс и состоит из нескольких полей. Длина поля в битах приведена внизу поля.
Маркер “00” размером в 1 байт означает, что за ним следуют незакодированные символы входного сообщения. Поле “длина” может содержать значение от 1 до 63, соответствующее количеству незакодированных символов. Если это значение равно 0, то следующие два байта содержат пару <количество_повторов, символ>, заменяющую повторяющий символ сообщения, а незакодирован¬ные символы отсутствуют.
Маркер “01” размером в 2 байта состоит из трех полей. Первое 2-битовое поле содержит количество (от 0 до 3) незакодированных символов, следующих сразу за маркером. Второе 3-битовое поле — длину совпадения (от 3 до 10 символов), а третье 9-битовое поле содержит смещение назад (!) от текущей позиции (от 0 до 511).
Маркер “10” размером в 2 байта состоит из двух полей. Первое 2-битовое поле содержит длину совпадения (от 3 до 6 символов), а второе 12-битовое поле — смещение назад от текущей позиции.
Маркер “11” размером в 3 байта состоит из трех полей. Первое 4-битовое поле содержит количество (от 0 до 15) незакодированных символов, следующих сразу за маркером. Второе и третье поля содержат пару <смещение, длина>, причем смещение может принимать значение от 0 до 8191, а длина — от 0 до 31.
Вместо обычного для LZSS набора <0, незакодированный байт>, <1, 12 битов — смещение, 4 бита — длина совпадения> используется несколько аналогичных, но более сложных кодов. Это позволяет добиться лучших результатов сжатия на коротких сообщениях.
Модель данных LZM
В отличие от алгоритма LZ77, в LZM для поиска повторяющихся подстрок сообщения используется хеш-таблица смещений строк относительно начала сжимаемого блока. Размер таблицы — 4096 значений. Индексом при входе в таблицу является 12-битовый хеш-код, получаемый по очередным трем символам сжимаемого сообщения. Для получения хеш-кода используется широко известная функция хеширования символьных строк.
ХЕШ_КОД = О
ХЕШ_КОД = Первый_Символ
ХЕШ_КОД = ХЕШ_КОД “ 2 (* Побитовый сдвиг *)
ХЕШ_КОД = ХЕШ_КОД хоr ВторойСимвол
ХЕШ_КОД = ХЕШ_КОД “ 2
ХЕШ_КОД = ХЕШ_КОД хоr ТретийСимвол
Хеш-таблица используется только при кодировании. Получаемые коды содержат достаточно информации для того, чтобы не поддерживать модель данных сообщения при декодировании.
Кодер LZM
Схема работы кодера LZM может быть описана следующим образом.
- Кодер пытается определить, возможно ли закодировать текущий фрагмент с помощью кодирования повторов (RLE). Если да, то кодер выдает соответствующий маркер (или их комбинацию), сбрасывает счетчик незакодированных символов, обновляет текущее смещение и переходит к пункту 1.
- Кодер строит значение хеш-функции для текущего смещения от начала сообщения, выбирает из таблицы по хеш-значению смещение подстроки с аналогичным значением хеш-функции от начала сообщения, заменяет этот элемент таблицы на текущее смещение. Затем ко¬дер пытается определить длину совпадения двух подстрок: с текущим смещением и со смещением из таблицы. Если длина совпадения больше 2, то кодер выдает наиболее подходящий маркер (или их комбинацию) и сбрасывает счетчик незакодированных символов. Иначе кодер увеличивает счетчик пропущенных символов. Кодер обновляет текущее смещение и переходит к пункту 1. В силу того, что длина сжимаемого сообщения известна, вопрос об остановке кодера не вызывает сложностей.
Декодер LZM
Алгоритм работы декодера очень прост.
- Прочитать один байт. В зависимости от пре¬фикса прочитать весь маркер.
- Прочитать из маркера количество незакодированных символов, смещение и длину совпадения. Если это маркер
“00” и количество незакодированных символов равно 0, то выдать соответствующее количество одинаковых символов в выходной буфер. Иначе: - скопировать необходимое количество очередных символов в выходной поток (несжатая информация);
- скопировать указанное количество символов выходного потока, находящихся на указанном смещении от текущей позиции, в выходной поток. (Декодирование повторяющейся подстроки сообщения.)
Перейти к пункту 1.
Сравнение с LZSS: плюсы и минусы
Когда речь идет об алгоритмах сжатия информации, то нужно очень хорошо отдавать себе отчет в том, что требования к степени сжатия, быстродействию и объему памяти, необходимой для работы алгоритма, являются практически взаимоисключающими. Любая коммерческая программа сжатия информации является тем или иным компромиссом между этими требованиями. Так, алгоритм LZM, выигрывая у LZSS по быстродействию и памяти, проигрывает в степени сжатия. Где именно это происходит? Все дело в разных моделях данных, используемых алгоритмами. LZM не пытается запоминать упорядоченное дерево под¬строк сообщения, как LZSS, а только таблицу их хеш-кодов. Это и дает LZM существенное преимущество по памяти и скорости. Но, с другой стороны, для модели данных LZM все подстроки с одинаковым значением хеш-функции просто неразличимы, то есть модель сообщения LZM менее точна, чем у LZSS. Как раз это и приводит к уменьшению степени сжатия и к существенному выигрышу в скорости работы.
Заключение
LZM — это компактный и очень быстрый алгоритм, который дает хорошее сжатие, и ориентирован на использование в драйверах устройств. По своим суммарным характеристикам он уступает разве что алгоритму LZS фирмы Stac Electronics. Так, например, на файлах различных СУБД и картинках (BMP) сжатие достигает 5:1, текстовых файлах — 2: 1, текстах программ — 3:1, выполняемых файлах — 1,5:1.