|
||||||||
|
||||||||

|
Microsoft SQL Server 7.0 Decision
Support Services: снижение затрат на интеллектуальное управление делами
Оригинал статьи находится по адресу: http://www.microsoft.ru/msdn/Experts/SQLServer/SQL7_dss.htm
Введение
Оперативная аналитическая обработка (OLAP - Online analytical processing)
сегодня приобретает все большую популярность. Эта технология в состоянии резко
улучшить качество анализа в бизнесе, однако исторически с нею связана
дороговизна инструментов, трудность реализации и недостаточная гибкость
развертывания. Microsoft обратилась к проблемам OLAP и создала решение, которое
открывает доступ к многомерному анализу для гораздо более широкой аудитории и
при этом значительно снижает затраты. Служба поддержки принятия решений MicrosoftR Decision Support Services (DSS)
- это новый полноценный инструмент OLAP, поставляемый в качестве компонента
Microsoft SQL ServerT версии 7.0. DSS включает сервер промежуточного уровня,
позволяющий проводить сложный анализ больших объемов данных с исключительно
высокой производительностью. Второй компонент DSS представляет собой клиентский
механизм кэширования и вычислений, носящий название Microsoft PivotTable
Service. Эта служба помогает улучшить производительность и снизить трафик в
сети, а также дает пользователям возможность выполнять анализ после отключения
от корпоративной сети. OLAP играет ключевую роль в процессе создания хранилищ данных, так что DSS
обеспечивает важные функциональные возможности для широкого спектра приложений
- от подготовки корпоративных отчетов до мощных средств поддержки принятия
решений. Включение функций OLAP в SQL Server сделает многомерный анализ гораздо
более доступным и позволит более широкой аудитории воспользоваться плодами
OLAP. Это затронет не только небольшие организации, но также группы и отдельных
сотрудников в рамках крупных корпораций, которых изолировали от индустрии OLAP
высокая стоимость и сложность существующих на рынке продуктов. В сочетании с широким набором инструментов и продуктов, поддерживающих
приложения OLAP с помощью интерфейса Microsoft OLE DB for OLAP, DSS поможет
расширить круг организаций, имеющих доступ к изощренным средствам анализа, а
также снизить затраты на организацию хранилищ данных. Потребность в OLAP
Рост спроса на хранилища данных и витрины данных
Исторически большая часть инвестиций в корпоративные вычислительные средства
была связана с системами, которые порождают или фиксируют данные, например, в
бухгалтерском учете, обработке заказов, производстве и системах информации о
клиентах. Сейчас организации вкладывают все больше ресурсов в приложения и
технологии, которые позволяют извлечь из таких собранных данных дополнительную
выгоду. Термин "создание хранилищ данных" (data warehousing) описывает процесс
сбора, очистки и просеивания данных из различных рабочих систем, а также
предоставление широкой аудитории бизнес-пользователей доступа к полученной
информации для анализа и подготовки отчетов. Постоянные хранилища очищенной и
систематизированной информации, доступные для просмотра пользователями,
называются хранилищами данных
или витринами данных
(data marts). Стратегия Microsoft в области создания хранилищ
данных
Несколько лет назад Microsoft выдвинула несколько инициатив, направленных на
увеличение доступности средств создания хранилищ данных и поддержки принятия
решений в бизнесе. Это архитектура создания хранилищ данных Microsoft Data
Warehousing Framework, лежащая в основе разработки продуктов Microsoft, а также
коалиция Microsoft Alliance for Data Warehousing, которая помогает партнерам,
ориентирующимся на платформу Microsoft и Data Warehousing Framework, соединять
усилия в области разработки и маркетинга. Эти инициативы опирались на базовую
стратегию Microsoft, предполагающую улучшение процесса создания хранилищ данных
за счет:
Microsoft Data Warehousing
Framework Data Warehousing Framework - это открытая архитектура, описывающая механизмы
обмена данными и метаданными в процессе построения и управления хранилищами и
витринами данных. К числу основных технологий, лежащих в ее основе, принадлежат
интерфейсы доступа к данным OLE DB и работающий на SQL Server экземпляр Microsoft
Repository. Этот репозитарий представляет собой базу данных, где хранится
полная информация о программных компонентах и их отношениях (метаданные). В
рамках Microsoft Repository определены модели метаданных для схем баз данных,
преобразований данных и схем баз данных OLAP.
Архитектура Microsoft Data Warehousing Framework подробно описана в другой
публикации по SQL Server, которая называется "Стратегия
Microsoft в области создания хранилищ данных". Сложность данных
Хотя в процессе создания хранилища данных эти данные становятся более
пригодными для работы пользователей, большая часть информации в реляционном
хранилище данных не обеспечивает простого просмотра. Бизнес-пользователям часто
трудно понять структуру данных, а бизнес-вопросы аналитического характера
(например, "Какие торговые представители в каждом регионе добились лучших
результатов по месяцам прошлого года?") очень сложно выражаются на языке
реляционных запросов SQL. Некоторые из этих проблем можно разрешить с помощью
мощных инструментов создания запросов, которые скрывают сложность базы данных
от пользователя. Однако для большого класса приложений, где пользователи
рассматривают многомерные
данные, оптимальным решением является технология OLAP. С многомерными данными сталкиваются организации, работающие в любой области
бизнеса, и сложность данных не обязательно напрямую зависит от размера
компании. Даже самой маленькой компании хотелось бы отслеживать продажи в
зависимости от продукта, торгового представителя, географии, клиента и времени.
Каждая из этих описательных категорий представляет собой отдельное измерение в
модели OLAP. Организации давно искали средства, позволяющие легко и естественно
получать, просматривать и анализировать многомерные данные. Концепция OLAP не нова, однако имя "OLAP" эта технология получила лишь
недавно, когда она стала более популярной. Д-р Е.Ф. Кодд, известный
исследователь баз данных и изобретатель реляционной модели, предложил этот
термин в 1993 г. в статье, где сформулированы 12 правил, определяющих основные
характеристики OLAP-приложений. Позднее Найджел Пендс и Ричард Крит из OLAP Report
уточнили его определение, предложив так называемый тест FASMI. Этот критерий
просто утверждает, что OLAP-приложения должны обеспечивать быстрый анализ
разделяемой многомерной информации (Fast Analysis of Shared
Multidimensional Information): быстрый Они должны доставлять пользователю информацию с относительно постоянной
скоростью, а выполнение большинства запросов должно занимать не более пяти
секунд. анализ Они должны быть в состоянии выполнять базовые операции численного и
статистического анализа данных - как заранее определенные разработчиком
приложения, так и специально заданные пользователем. разделяемой Они должны реализовать требования безопасности, необходимые для совместного доступа
большого числа пользователей к потенциально конфиденциальным данным. многомерной Это важнейшая характеристика OLAP. информации Они должны быть в состоянии получать доступ ко всем связанным с приложением
данным и информации независимо от места их хранения и без ограничений по
объему. Ценность для бизнеса
OLAP предоставляет организациям наиболее гибкие и производительные средства
доступа, просмотра и анализа данных, связанных с бизнесом. Прежде всего, OLAP
представляет данные пользователям с помощью естественной, интуитивной модели
данных. Благодаря легкости перемещения по данным бизнес-пользователи могут
более эффективно просматривать и анализировать информацию из своих хранилищ
данных, что позволяет организациям лучше осознать ценность этих данных.
Во-вторых, OLAP ускоряет доставку информации пользователям, просматривающим
такие многомерные структуры. С этой целью подготовка некоторых вычисляемых
значений в массиве данных осуществляется заранее, а не во время выполнения.
Сочетание легкости перемещения и высокой производительности помогает
пользователям просматривать и анализировать данные гораздо быстрее и
эффективнее, чем это было бы возможно только на основе технологии реляционных
баз данных. В результате они посвящают больше времени анализу данных и меньше -
анализу баз данных. Термины и концепции OLAP
Модель данных OLAP
В рамках каждого измерения модели данных OLAP данные могут быть организованы
в виде иерархии,
представляющей различные уровни их детализации. Например, в измерении "Время"
можно выделить уровни "Годы", "Месяцы" и "Дни". Точно так же в рамках измерения
"География" вы могли бы ввести уровни "Страна", "Регион", "Штат/провинция" и
"Город". Каждая конкретная модель OLAP будет включать определенные значения для
каждого уровня иерархии. При просмотре данных OLAP пользователь будет
перемещаться вверх и вниз между уровнями данных, чтобы увидеть больше деталей
или получить сводную информацию. Альтернативные способы хранения
Кубы, измерения, иерархии и меры - это основа многомерной навигации в OLAP.
Благодаря такому способу описания и представления данных пользователи могут
легко и интуитивно перемещаться по сложному набору данных. Однако простое
описание модели данных с помощью более интуитивного представления мало помогает
быстрее доставить информацию пользователю. Ключевой принцип OLAP предполагает,
что время отклика должно быть примерно одинаковым для любого запрошенного
пользователем представления, или среза
(slice), данных. Поскольку данные, как правило, собираются только на детальном
уровне, сводную информацию о них обычно вычисляют заранее. Такие заранее
рассчитанные значения, или агрегаты
(aggregations), лежат в основе связанного с OLAP прироста производительности. На заре развития технологии OLAP большинство производителей считало, что
единственное возможное решение при создании OLAP-приложений связано с использованием
специализированной, нереляционной модели хранения. Позднее другие производители
обнаружили, что применение определенных структур базы данных (схемы "звезда" и
"снежинка"), индексации и хранения агрегатов позволяет использовать для OLAP
реляционные системы управления базами данных (РСУБД). Такие производители
назвали свою технологию Relational OLAP (ROLAP). Поставщики более старых систем
затем приняли термин MOLAP (multidimensional OLAP - многомерная OLAP). В течение последних нескольких лет между сторонниками MOLAP и ROLAP шли
жаркие дебаты. Реализации MOLAP обычно превосходят реляционную технологию по
производительности, но испытывают проблемы с масштабируемостью. С другой
стороны, реализации ROLAP обеспечивают более высокую масштабируемость и часто
оказываются привлекательными для пользователей, поскольку позволяют опереться
на инвестиции в реляционную технологию, связанные с существующими базами
данных. Недавно были разработаны гибридные решения для OLAP, которые иногда называют
HOLAP (hybrid OLAP). Одновременно используя архитектуры ROLAP и MOLAP, они
соединяют лучшие черты обоих решений - превосходную производительность и
высокую масштабируемость. Один из подходов к созданию HOLAP включает в
реляционную базу данных записи с детальной информацией (занимающие наибольший
объем) и в то же время помещает агрегаты в отдельное хранилище архитектуры
MOLAP. Архитектура Decision Support Services
Серверный компонент DSS Analysis Server выполняется как служба Microsoft
Windows NTR и обеспечивает базовые вычислительные функции. Программный доступ к
функциям управления Analysis Server осуществляется с помощью объектной модели
Decision Support Objects (DSO), спецификация которой опубликована Microsoft.
Встроенный административный интерфейс пользователя DSS (OLAP Manager) также
опирается на DSO и предлагает богатые возможности управления, не требующие
написания программ. Инструменты OLAP Manager и Analysis Server допускают
выполнение на разных компьютерах. Используя OLAP Manager, администратор баз
данных может, в частности, проектировать модели баз данных OLAP, получать
информацию из реляционных хранилищ (РСУБД), строить агрегаты и заполнять
хранилища данных OLAP. Определения метаданных OLAP находятся в отдельном
репозитарии, но с помощью простой утилиты их можно экспортировать в Microsoft
Repository с поддержкой OLAP Information Model. DSS может получать исходные данные от любого источника данных OLE DB. Среди
них - не только SQL Server, но и большое число СУБД для настольных систем и
серверов, включая Microsoft Access, Microsoft FoxPro, Oracle, Sybase, Informix
и т.д. Возможен также доступ к любым источникам баз данных, поддерживающим
интерфейс ODBC, поскольку OLE DB позволяет "обернуть" драйверы ODBC и работать
с ними так, как будто они предоставляют естественный интерфейс OLE DB. Кроме
того, эти источники данных могут находиться на других платформах, отличных от
операционной системы Windows NT - например, на Unix-системах или мэйнфреймах в
таких базах данных, как DB2 или Teradata. Благодаря межплатформным возможностям
OLE DB к данным на широком спектре систем можно обращаться точно так же, как
если бы они были локальными для DSS-сервера. DSS также включает клиентский компонент PivotTable Service, который подробно
описывается позднее в этом документе. Пока его достаточно рассматривать как
средство, соединяющее клиентские приложения OLAP с сервером DSS. Любой доступ
специализированных программ или клиентских инструментов к данным, находящимся
под управлением DSS, осуществляется с помощью реализованного в PivotTable
Service интерфейса OLE DB for OLAP. Как клиентский, так и серверный компоненты DSS допускают расширение их
функций. Благодаря хорошо документированным средствам DSO пользователи,
независимые производители программ и консультанты в состоянии расширять
вычислительные возможности, средства управления данными или создания
приложений. Такая встроенная расширяемость обеспечивает пользователям
постоянную уверенность в том, что DSS будет обладать характеристиками, которые
необходимы для удовлетворения потребностей их приложений. Преодолевая проблемы реализации OLAP
Проблема ©1: построение модели данных OLAP
Установление соответствия между исходной схемой базы данных и многомерной
моделью представляет собой фундаментальную проблему реализации OLAP. Во многих
продуктах, присутствующих сегодня на рынке, для этого требуются значительные
усилия программистов. За годы эволюции продуктов OLAP проектирование базы
данных OLAP превратилось в специализированный и таинственный процесс, который
сложным образом переплетается с конкретной используемой технологией OLAP. Это
приводит к глубокой специализации разработчиков баз данных OLAP, так что
разработка приложений требует больших затрат, связанных в основном с этапом
проектирования данных. В большинстве реализаций OLAP предполагается, что данные для анализа уже
подготовлены при создании хранилища данных. Это означает, что перед включением
информации в OLAP-приложение она извлекалась из рабочих систем, а также
проводилась ее очистка, проверка и вычисление сводных характеристик. Этот этап
очень важен, поскольку он гарантирует, что пользователь OLAP увидит точные и
согласованные данные, соответствующие принятым в организации определениям.
На этой иллюстрации представлен пример схемы "звезда". При использовании
такой схемы базы данных центральная таблица "факты" связывается с родственными таблицами
атрибутов, или измерений. Интуитивный пользовательский
интерфейс обеспечивает доступность Одна из важнейших отличительных черт DSS - это пользовательский интерфейс
OLAP Manager, созданный в расчете на администратора баз данных OLAP, который
работает с системой не слишком часто. DSS OLAP Manager представляет собой
подключаемый модуль Microsoft Management Console (MMC) и использует такой же
административный интерфейс пользователя, как SQL Server и линия продуктов
Microsoft BackOfficeR. Очевидная выгода такого решения в том, что
администратору легче опереться на навыки работы с SQL Server и другими
продуктами Microsoft, однако после знакомства с мощностью и гибкостью MMC
проявляются еще более ценные преимущества. DSS включает полный набор "блокнотов"
(taskpads), которые помогают начинающему или нерегулярному пользователю
справиться с типичными задачами. Кроме того, вместе с DSS поставляется
исчерпывающий учебный курс по концепциям OLAP и подробное руководство,
охватывающее все этапы построения куба OLAP. Доступен также широкий спектр
мастеров для автоматизации наиболее частых операций, например, для задания
характеристик измерения. Более того, архитектура DSS оптимизирована для разработок на базе хранилищ
данных, использующих схемы "звезда" и "снежинка". Мастер создания куба (Cube
Creation Wizard) особенно хорошо приспособлен к таким готовым схемам, и переход
к многомерной модели осуществляется чрезвычайно быстро. Впрочем, DSS легко
может приспособиться и к другим исходным схемам, если таковые встретятся в
конкретной задаче. Чтобы гарантировать успешную интерпретацию принципов пользовательского
интерфейса DSS, в лабораториях Microsoft было проведено значительное число
тестов с добровольцами для проверки удобства работы с ним. Наконец,
крупномасштабное бета-тестирование, включавшее рекордное для индустрии OLAP
число пользователей, позволило широким кругам клиентов познакомиться с DSS и
сформулировать свои замечания. Благодаря усилиям, затраченным на удовлетворение
требований администраторов баз данных, большинству пользователей удалось
построить первый куб менее чем за 30 минут. Проблема ©2: взрыв данных при агрегации
Существует множество примеров того, как такой взрыв данных проявляется в
реальном мире. Опубликованные недавно результаты стандартного теста
производительности другого OLAP-приложения указывают на коэффициент взрыва
данных около 240, так что для управления 10 Мб входных данных потребовалась
емкость устройства хранения 2,4 Гб (гигабайта). Необходимость установки
дисковых устройств хранения с объемом, достаточным для такого большого
расширения данных, в условиях крупных систем OLAP приводит к значительным
затратам. Кроме того, она жестко ограничивает способность организации
анализировать все желаемые исходные данные.
Для разработчиков OLAP разреженные данные всегда представляли собой
проблему, которую они решали с большим или меньшим успехом. Наиболее неудачные
реализации сохраняют в базах данных пустые значения, что приводит к очень
низкой плотности хранения, а также бесполезному расходу места и ресурсов. DSS
не хранит пустые значения, так что даже редко населенные кубы не раздуваются в
объеме. Хотя некоторые поставщики часто выделяют эту проблему как решающий
фактор при выборе архитектуры OLAP, на самом деле различия между реализациями
по способу управления разреженными данными весьма незначительны по сравнению с
гораздо более существенным взрывом данных, который вызывается предварительным
вычислением слишком большого числа агрегатов. Гибкий выбор способа хранения
улучшает использование ресурсов DSS впервые на рынке OLAP смог предложить гибкое решение, позволяющее администратору
баз данных OLAP самому выбрать наиболее удачную модель хранения. DSS
поддерживает полную реализацию MOLAP, полную реализацию ROLAP и гибридные
системы, в которых агрегаты сохраняются как с помощью многомерной, так и с
помощью реляционной технологии. Например, администратор мог бы поместить часто
используемые данные (скажем, по текущему году) в MOLAP, а исторические данные
(вызывающие больше проблем с масштабируемостью) - в ROLAP. В то же время
базовая модель данных совершенно закрыта от клиентского приложения, и его
пользователь видит только кубы. DSS обеспечивает превосходную интеграцию с реляционными базами данных
независимо от того, решил ли администратор реализовать модель данных MOLAP,
ROLAP или HOLAP. Непосредственно соединяя графические инструменты
проектирования и мастера с OLE DB, DSS поддерживает очень крепкие связи между
исходными данными, многомерными метаданными OLAP и самими агрегатами. При реализации моделей данных ROLAP он определяет, заполняет и поддерживает
все структуры реляционной базы данных. Эта особенность освобождает разработчика
от необходимости самому выполнять эти операции или, хуже того, управлять
сложными запросами с обращением к нескольким таблицам и серверам. Интеллектуальная предварительная
агрегация DSS также сводит к минимуму влияние фундаментальной проблемы технологии OLAP
- взрыва данных, вызываемого избыточным предварительным вычислением агрегатов.
Как показано выше, взрыв данных в OLAP является результатом многомерной
предварительной агрегации. В традиционных системах OLAP данные, не прошедшие
такой агрегации, оказываются недоступными для целей анализа и построения
отчетов, если только их не вычислять во время выполнения. Предварительное
вычисление и сохранение всех возможных комбинаций агрегатов (например, сумма
всех продуктов и уровней продуктов по всем периодам времени, по всем
организациям, по всем каналам распространения и т.д.) в традиционных продуктах
OLAP приводит к мощному взрыву данных. В отличие от такого подхода "грубой силы", требующего вычисления всех
возможных агрегатов, DSS может определить, какие агрегаты обеспечивают
наибольший выигрыш в производительности. Кроме того, он позволяет
администратору сделать выбор между скоростью системы и дисковым пространством,
необходимым для управления агрегатами. Если разработчик решит предварительно
вычислить все агрегаты, требования к дисковому пространству будут максимальными
(что приведет к синдрому взрыва данных). С другой стороны, если разработчик
ничего не будет рассчитывать, требования к диску окажутся нулевыми, но
улучшения производительности не произойдет.
Хотя DSS включает превосходные средства эвристического анализа, все они
основаны на математических моделях, которые могут соответствовать, а могут и не
соответствовать фактическим закономерностям использования системы. Для
оптимизации производительности в соответствии с реальными закономерностями DSS
в состоянии вести протокол запросов, переданных серверу. Затем этот протокол
можно использовать для тонкой настройки поддерживаемого DSS набора агрегатов.
Например, простой мастер позволяет администратору базы данных создать новый
набор агрегатов для всех запросов, ответ на которые потребовал свыше n секунд
(где n может составлять 10 секунд или больше). Во многих организациях время обработки более важно, чем дисковое
пространство. Дополнительный диск всегда можно купить, однако если для
обработки дневной порции новых данных нужен целый день, то дополнительное время
купить просто негде. Тем не менее, реализованное в DSS решение проблемы взрыва
данных снижает время, необходимое для обработки первоначального массива данных
и инкрементальных обновлений, а также сводит к минимуму необходимый объем
дискового пространства. Если приложение начинает с хранилища данных объемом 10
Гб и генерирует 10 Гб агрегатов, то время обработки будет составлять малую долю
времени, которое потребовалось бы для обработки полностью развернутого набора
агрегатов. DSS также использует новаторский подход к проблеме разреженных данных. Хотя
детали его внутренней реализации являются закрытыми, общий результат состоит в
том, что реализации MOLAP и ROLAP очень хорошо управляют хранением данных. В
действительности это может приводить к созданию баз данных, требующих для
хранения данных OLAP меньше места, чем для исходных детальных данных. Виртуальные кубы могут найти применение в любой ситуации, когда пользователь
хотел бы рассматривать объединенную информацию из двух непохожих кубов, которые
могут включать всего одно общее измерение. Эта идея похожа на реляционные
представления, поскольку виртуальный куб состоит из двух или нескольких кубов,
соединяемых в момент запроса по одному или нескольким общим измерениям. Одно из
преимуществ виртуальных кубов проявляется в ситуациях, где значительную
проблему представляет разреженность данных. Например, пусть куб содержит меры
продаж в единицах и фактической цены продажи. Для вычисления скидок в него
можно было бы включить также меру цены по каталогу, однако ее значение будет
много раз повторяться. Построив куб цены по каталогу и соединив его в
виртуальном кубе с фактической информацией о продажах, администратор базы
данных может в большой степени устранить избыточность данных. Возможность
создания виртуальных кубов означает, что многие ненужные значения можно вообще
удалить из хранилища данных OLAP. Производительность и
масштабируемость Конкретные значения производительности OLAP-приложения являются функцией от
нескольких факторов, в том числе размера базы данных, мощности аппаратного
обеспечения и объема дискового пространства, выделенного для агрегатов данных.
Тем не менее, в реальных системах приложения DSS отвечают на большинство
запросов менее чем за пять секунд и практически на все запросы - в течение
десяти секунд. Высокая масштабируемость технологии DSS обеспечивается новаторской
реализацией разбиения
кубов (partitioned cubes). Благодаря такому разбиению один логический куб
данных может охватывать несколько физических кубов и даже несколько разных
физических серверов. Получив запрос пользователя, DSS распределяет его между
участвующими в разбиении серверами, что позволяет извлекать данные параллельно.
В качестве примера давайте рассмотрим приложение, которое отслеживает
телефонные звонки в десяти географических регионах, так что в день можно
ожидать несколько миллионов звонков. Предположим, что эти данные разбиты между
десятью серверами, каждый из которых содержит данные по определенному региону.
В то же время с точки зрения пользователя здесь существует только один
логический куб данных. Когда пользователи запрашивают эту информацию, DSS
прозрачно преобразует запросы для каждого из десяти серверов и возвращает
пользователю единый набор результатов. К каждой из десяти индивидуальных баз
данных также можно обратиться по отдельности, если аналитика интересует только
информация по этому конкретному региону. Способность DSS эффективно управлять
данными, разбитыми по нескольким серверам, делает эту технологию гораздо более
масштабируемой по сравнению со многими конкурирующими решениями. Проблема ©3: доставка информации пользователю OLAP
Исторически серверная технология OLAP всегда была тесно связана с закрытой
клиентской технологией, так что пользователь не мог подобрать смешанное решение
из лучших в своем классе продуктов. Это приводило к очень высоким затратам на
реализацию, а часто и к неудовлетворительным результатам в приложениях, которые
требовали доставки информации OLAP как в клиент-серверной среде, так и с помощью
Web. Как и несколько лет назад на рынке реляционных баз данных, очевидной стала
необходимость единого интерфейса, способствующего открытости выбора приложений
и баз данных. В этом примере таким стандартом стал интерфейс ODBC. Промышленные стандарты
Первая попытка решения проблемы открытости инструментов OLAP была
предпринята в 1996 г. Консорциум производителей, названный OLAP Council,
представил стандарт интегрируемости MDAPI, который должен был открыть рынок для
более широкого круга поставщиков. Несмотря на значительные ожидания
пользователей, сообщество производителей - включая и членов OLAP Council - в
основном игнорировало этот интерфейс. Сознавая необходимость единого стандарта, опирающегося на предшествующие
инвестиции клиентов, Microsoft решила расширить определение существующего
интерфейса доступа к данным OLE DB, включив в него возможности работы с
многомерными данными. В течение почти целого года Microsoft опубликовала два
проекта API, организовала его свободное обсуждение производителями и пользователями
и наконец выпустила в феврале 1998 г. окончательную спецификацию, которая уже в
бета-версии получила поддержку 18 производителей. Сегодня интерфейс OLE DB for OLAP поддерживают более тридцати
производителей, многие из которых перечислены на веб-узле Microsoft по адресу http://www.microsoft.com/data/oledb/olap.
Этот список включает почти всех членов OLAP Council, находящегося сегодня в
упадке. Многие из них уже предлагают бета-версии продуктов, основанных на этой
спецификации и доступных пользователям DSS. Указатель производителей, чьи
продукты в настоящее время поддерживают Microsoft DSS, можно найти по адресу http://www.microsoft.com/sql/dss.
Доставка без подключения к сети и
с помощью Web Многие бизнес-аналитики сталкиваются с необходимостью многомерного анализа
данных без подключения к корпоративной сети, например, при работе с переносным
компьютером в дороге. Как правило, мобильным пользователям нужно просматривать
и анализировать лишь небольшие срезы полного куба. Так, при посещении
региональных офисов менеджер по продажам мог бы взять с собой сводные данные по
доходам в конкретном регионе. Такая потребность настолько типична, что для нее
даже было придумано новое сокращение DOLAP (Desktop OLAP - настольная OLAP),
которое описывает задачи, не требующие использования разделяемого сервера для
доступа к многомерным данным. Большинство доступных сегодня серверных технологий OLAP не обеспечивает
прозрачного создания кубов для настольной OLAP. В результате этот этап еще
больше увеличивает усилия разработчиков или выпадает на долю клиентских
инструментов OLAP, которые теперь вынуждены включать функции поддержки настольного
использования. В итоге возрастает стоимость и сложность создания приложений,
требующих работы клиентов как с подключением, так и без подключения к сети. Сегодня веб-браузер представляет собой наиболее популярное средство
просмотра для любых типов информации, и OLAP не является здесь исключением. В
крупномасштабных OLAP-приложениях браузеры могут стать основным фактором
снижения стоимости в расчете на одного пользователя, обещая открыть мир
многомерного доступа к данным для гораздо более широкой аудитории. В настоящее
время имеется несколько очень хороших продуктов и инструментов для доставки
данных OLAP по интрасети, однако не существует простых механизмов, позволяющих
разработчику приложения создавать специализированные средства просмотра OLAP. Microsoft PivotTable Service Сервер DSS осуществляет не только кэширование данных, но также и
пользовательских запросов и метаданных. Сохраненные в кэше определения запросов
и метаданных позволяют ему при ответе на новые запросы вычислять результат по
данным из кэша, а не обращаться к диску. Например, пусть один пользователь
запросил данные о продажах за январь, февраль и март. Когда другой пользователь
просит данные по первому кварталу, суммирование находящейся в памяти информации
за январь-март потребует от DSS гораздо меньше времени, чем загрузка данных
первого квартала с диска. Однако это только половина истории, и здесь DSS не
слишком отличается от большинства других серверов OLAP.
Интеллектуальная клиент-серверная архитектура DSS в состоянии определить,
как быстрее всего ответить на вопрос пользователя, и устранить избыточный
сетевой трафик. Ключом к этому является совместное использование метаданных
клиентом и сервером. Когда пользователь запрашивает с сервера информацию, на
клиент загружаются как данные, так и метаданные (определения структуры куба).
Благодаря наличию на клиенте метаданных для куба PivotTable Service может
выяснить, какие вопросы для решения необходимо вернуть на сервер. В качестве примера давайте вспомним сценарий с данными по продажам за три
месяца. Предположим, что и сервер DSS, и клиентское приложение только что были
запущены. Когда пользователь запрашивает данные за январь, февраль и март, они
помещаются в кэш как на сервере, так и на клиенте. Если пользователь после
этого попросит данные за первый квартал, PivotTable Service вычислит результат
локально (на клиенте), не посылая запрос на сервер. Затем пользователь может
захотеть сравнить данные по продажам за первый квартал этого и предыдущего
года. PivotTable Service обладает достаточной интеллектуальностью, чтобы
обращаться на сервер только за данными прошлого года. PivotTable Service также включает механизм поддержки мобильного
использования. Фрагменты кубов, определенные и полученные с сервера, можно
сохранять на клиенте для последующего доступа без подключения к сети. Таким
образом, бизнес-пользователи могут брать какие-то части базы данных с собой в
дорогу и даже вне стен офиса по-прежнему располагать всеми возможностями
анализа данных. Кроме того, эта служба позволяет пользователям создавать
простые локальные OLAP-модели, получая информацию из совместимых с OLE DB
источников данных - от плоских файлов до СУБД для настольных компьютеров. Наконец, PivotTable Service обеспечивает возможности связывания с
веб-приложениями. Хотя OLE DB for OLAP представляет собой программный интерфейс
низкого уровня, было разработано также новое расширение ActiveX Data Objects
(ADO), поддерживающее многомерный доступ к данным. Эти расширения, носящие
название ADO/MD, легко можно использовать для создания с помощью Microsoft
Visual BasicR управляющих элементов ActiveXR, позволяющих просматривать, строить
диаграммы и генерировать отчеты по данным DSS в рамках веб-страницы. ADO/MD -
это инструмент, открывающий разработчику корпоративных приложений доступ ко
всем функциональным возможностям DSS. Проблема ©4: доступность инструментов OLAP
DSS ломает все ценовые ожидания, сложившиеся в индустрии OLAP. Как правило,
цена продуктов OLAP может составлять от 50 до 100 тысяч долларов за несколько
десятков пользователей. Microsoft осознала, что OLAP является естественным
расширением технологии баз данных, и поэтому реализовала DSS как функцию SQL
Server 7.0. SQL Server 7.0 включает множество других возможностей, которые дополняют DSS
и помогают в процессе создания хранилищ данных. В их числе:
Интеграция с Microsoft Office
Microsoft Office 2000 будет включать богатый набор возможностей просмотра
OLAP, совместимых с DSS. Эти средства, опирающиеся на интерфейсы OLE DB for
OLAP, поддерживают прямой доступ к серверам DSS, использование без подключения
к сети и доступ через Web. Прежде всего, новая функция PivotTable в рамках
Microsoft Excel будет обеспечивать связь электронных таблиц Excel и источников
данных OLE DB for OLAP. В случае, когда в качестве такого источника выступает
DSS, пользователю доступны дополнительные возможности. Например, он в состоянии
создать локальный куб на основе среза большого куба, хранящегося на сервере. Механизм PivotTable Service из DSS заменит в Microsoft Excel существующий
механизм PivotTableR. В результате пользователи настольных систем получат
большую гибкость создания многомерных структур, которые свободны от ограничений
по памяти, характерных для динамических представлений в сегодняшней PivotTable.
Наконец, входящий в будущую версию Office новый набор средств, названный Web
Components, будет обеспечивать доступ к простым возможностям просмотра и
построения диаграмм OLAP с помощью управляющих элементов ActiveX, допускающих
включение в любую веб-страницу. И снова, поскольку эти элементы опираются на
OLE DB for OLAP, их можно использовать с любым совместимым источником данных
OLAP, в том числе DSS. Включая в Microsoft Office базовые возможности просмотра и анализа OLAP,
Microsoft выполняет данное в рамках стратегии создания хранилищ данных обещание
снизить стоимость приобретения инструментов поддержки принятия решений для настольных
систем. Клиентские инструменты независимых
производителей Быстрое признание OLE DB for OLAP также привело к тому, что другие
разработчики программ выпустили широкий набор продуктов, предназначенных для использования
с DSS. Поскольку для доступа к информации в DSS доступно множество новых и уже
известных клиентских инструментов и компонентов, покупатели могут более
свободно подбирать решения в соответствии с требованиями их приложений и лучше
ограничивать затраты на приобретение клиентских средств. Заключение
Множество характеристик SQL Server 7.0, ориентированных на создание хранилищ
данных, обеспечивает Microsoft лидирующие позиции в отрасли и помогает
расширить рынок хранилищ данных благодаря появлению более доступных программ.
Такие продукты, как Decision Support Services, опираются на архитектуру
Microsoft Data Warehousing Framework и показывают путь к реализации функций
хранилища данных с меньшими затратами и сложностью, чем это было возможно ранее.
В сочетании с новыми возможностями просмотра OLAP в Microsoft Office они
гарантируют: выбрав семейство продуктов Microsoft для создания хранилищ данных
и приложений поддержки принятия решений, покупатели получают решение, которое
сможет расти вместе с их бизнесом, а также расширяться, включая широкий набор
лучших в отрасли инструментов. Информация,
содержащаяся в этом документе, представляет текущую точку зрения корпорации
Microsoft на обсуждаемые вопросы на момент публикации. Поскольку Microsoft
должна реагировать на изменяющиеся условия на рынке, документ не следует
рассматривать как обязательство со стороны Microsoft; корпорация Microsoft не
может гарантировать, что вся представленная информация сохранит точность после
даты публикации. Настоящий документ
предназначен только для информационных целей. MICROSOFT НЕ ДАЕТ В ЭТОМ
ДОКУМЕНТЕ НИКАКИХ ЯВНЫХ ИЛИ ПОДРАЗУМЕВАЕМЫХ ГАРАНТИЙ. c1998 Microsoft Corporation. Все права защищены. Microsoft, ActiveX, BackOffice, логотип BackOffice, Fox Pro, PivotTable, Visual Basic и Windows NT представляют собой зарегистрированные торговые марки либо торговые марки корпорации Microsoft в США и/или других странах. Другие упоминаемые
здесь названия продуктов или компаний могут представлять собой торговые марки
соответствующих владельцев. Если не оговорено
противное, используемые в этом документе названия компаний и продуктов, имена
людей, действующие лица и/или данные являются вымышленными, и их ни в коей мере
не следует связывать с какими-либо реальными людьми, компаниями, продуктами или
событиями. | ||||||||||
|
За содержание страницы отвечает Гончарова М.Н. © Кафедра СПиКБ, 2002-2017 |
|||||||||||

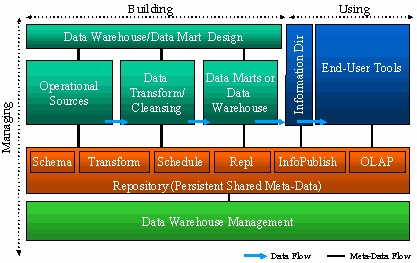 Компоненты Data
Warehousing Framework связаны с неотъемлемыми этапами процесса создания
хранилищ данных. Некоторые из них поставляются Microsoft, однако пользователи и
бизнес-партнеры Microsoft легко могут расширять их с помощью альтернативных
технологий. Многие базовые компоненты, необходимые для построения и поддержки
хранилищ данных, входят в состав SQL Server 7.0. Это средства проектирования
базы данных с помощью графического конструктора схем, хранилища данных большой
емкости, возможности преобразования данных с помощью
Компоненты Data
Warehousing Framework связаны с неотъемлемыми этапами процесса создания
хранилищ данных. Некоторые из них поставляются Microsoft, однако пользователи и
бизнес-партнеры Microsoft легко могут расширять их с помощью альтернативных
технологий. Многие базовые компоненты, необходимые для построения и поддержки
хранилищ данных, входят в состав SQL Server 7.0. Это средства проектирования
базы данных с помощью графического конструктора схем, хранилища данных большой
емкости, возможности преобразования данных с помощью  В модели данных OLAP
информация представляется в виде
В модели данных OLAP
информация представляется в виде 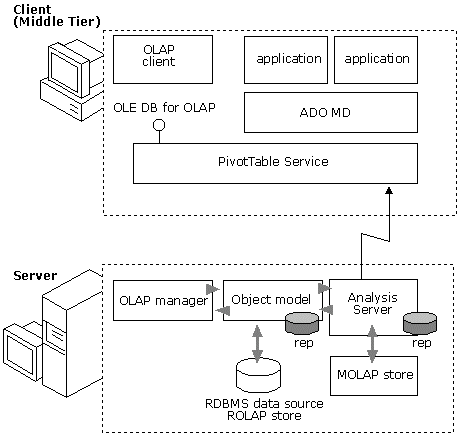 Все элементы архитектуры
DSS проектировались так, чтобы свести к минимуму основные затраты на построение
и поддержку OLAP-приложений. DSS включает как серверный, так и клиентский
программные компоненты.
Все элементы архитектуры
DSS проектировались так, чтобы свести к минимуму основные затраты на построение
и поддержку OLAP-приложений. DSS включает как серверный, так и клиентский
программные компоненты. 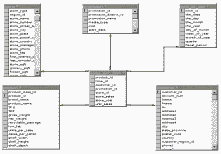 Разработчики хранилищ
данных все чаще применяют схемы "звезда" или "снежинка", которые упрощают
понимание данных пользователями, обеспечивают максимальную производительность
запросов в приложениях поддержки принятия решений и требуют меньше места для
хранения больших баз данных. Эти схемы представляют собой реляционные
приближения к модели данных OLAP и могут стать превосходной стартовой точкой
при создании определений кубов в OLAP. Тем не менее, преимущества, связанные с
этой тенденцией, используются лишь в немногих OLAP-продуктах. Как правило, они
не включают простых инструментов для перехода от схемы "звезда" к модели OLAP,
так что стоимость создания таких моделей остается очень высокой, а время
разработки - неоправданно большим.
Разработчики хранилищ
данных все чаще применяют схемы "звезда" или "снежинка", которые упрощают
понимание данных пользователями, обеспечивают максимальную производительность
запросов в приложениях поддержки принятия решений и требуют меньше места для
хранения больших баз данных. Эти схемы представляют собой реляционные
приближения к модели данных OLAP и могут стать превосходной стартовой точкой
при создании определений кубов в OLAP. Тем не менее, преимущества, связанные с
этой тенденцией, используются лишь в немногих OLAP-продуктах. Как правило, они
не включают простых инструментов для перехода от схемы "звезда" к модели OLAP,
так что стоимость создания таких моделей остается очень высокой, а время
разработки - неоправданно большим.  Как уже отмечалось, для
большинства продуктов OLAP предварительное вычисление агрегатов - это основная
стратегия, обеспечивающая выигрыш в производительности. В то же время
предварительная агрегация связана со значительными затратами: число агрегатов
легко может превысить число исходных точек с детальной информацией, что
приводит к резкому росту объема хранимых данных. В качестве примера рассмотрим
OLAP-модель всего с двумя измерениями и одним уровнем агрегации в каждом
измерении. Иллюстрация показывает, что в этом случае необходимо пять агрегатов,
что приводит к соотношению 2.25:1.
Как уже отмечалось, для
большинства продуктов OLAP предварительное вычисление агрегатов - это основная
стратегия, обеспечивающая выигрыш в производительности. В то же время
предварительная агрегация связана со значительными затратами: число агрегатов
легко может превысить число исходных точек с детальной информацией, что
приводит к резкому росту объема хранимых данных. В качестве примера рассмотрим
OLAP-модель всего с двумя измерениями и одним уровнем агрегации в каждом
измерении. Иллюстрация показывает, что в этом случае необходимо пять агрегатов,
что приводит к соотношению 2.25:1.  Синдром взрыва данных
может приводить к еще большим проблемам при разреженном распределении исходных
(детальных) данных по многомерному кубу. Отсутствующие или недопустимые
значения данных создают разрежение в модели данных OLAP, и в худшем случае
OLAP-продукт будет, несмотря на это, сохранять пустые значения. Например,
компания может продавать в каждом регионе не все свои продукты, так что в
таблице данных не будет значений, соответствующих определенным продуктам и
регионам. Эта иллюстрация отличается от предыдущей тем, что на Северо-востоке
не продается оборудование, а на Юго-востоке - программы.
Синдром взрыва данных
может приводить к еще большим проблемам при разреженном распределении исходных
(детальных) данных по многомерному кубу. Отсутствующие или недопустимые
значения данных создают разрежение в модели данных OLAP, и в худшем случае
OLAP-продукт будет, несмотря на это, сохранять пустые значения. Например,
компания может продавать в каждом регионе не все свои продукты, так что в
таблице данных не будет значений, соответствующих определенным продуктам и
регионам. Эта иллюстрация отличается от предыдущей тем, что на Северо-востоке
не продается оборудование, а на Юго-востоке - программы. 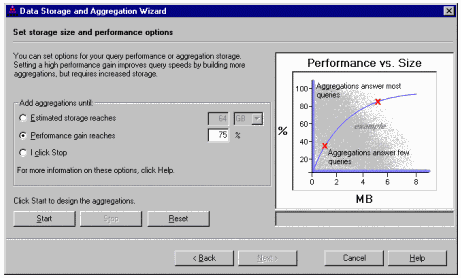 В большинстве случаев DSS
в состоянии добиться примерно 80%-го улучшения производительности запросов,
избегая излишнего вычисления агрегатов: экспоненциальный взрыв данных обычно
происходит на последних 20% агрегатов. DSS анализирует модель метаданных OLAP и
использует эвристические правила для определения оптимального набора агрегатов,
из которых можно получить все остальные. В результате DSS извлекает заранее не
агрегированные данные из нескольких существующих значений агрегатов, и ему не
нужно просматривать все хранилище данных. Тем не менее, такая стратегия
частичной предварительной агрегации представляет собой лишь исходный
пункт.
В большинстве случаев DSS
в состоянии добиться примерно 80%-го улучшения производительности запросов,
избегая излишнего вычисления агрегатов: экспоненциальный взрыв данных обычно
происходит на последних 20% агрегатов. DSS анализирует модель метаданных OLAP и
использует эвристические правила для определения оптимального набора агрегатов,
из которых можно получить все остальные. В результате DSS извлекает заранее не
агрегированные данные из нескольких существующих значений агрегатов, и ему не
нужно просматривать все хранилище данных. Тем не менее, такая стратегия
частичной предварительной агрегации представляет собой лишь исходный
пункт. 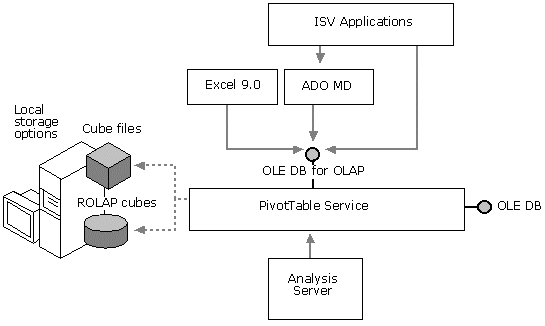 Уникальная особенность
DSS в том, что он обеспечивает во многом такие же возможности и на клиенте. Все
клиентские приложения связываются с серверами DSS с помощью клиентского
компонента, который называется Microsoft PivotTable Service. Эта служба играет
роль "драйвера", управляющего соединением между клиентом и сервером. Значительная
часть кода PivotTable Service совпадает с сервером DSS, так что она приносит
серверный механизм многомерных вычислений, функции кэширования и управления
запросами непосредственно на клиент. В результате мы получаем чрезвычайно
новаторскую клиент-серверную модель управления данными, которая оптимизирует
производительность и сводит к минимуму трафик в сети. Со всем этим связаны
очень небольшие затраты вычислительных ресурсов: для PivotTable Service
необходимо приблизительно 2 Мб дискового пространства, а потребность в памяти
составляет всего 500 Кб в дополнение к кэшируемым данным.
Уникальная особенность
DSS в том, что он обеспечивает во многом такие же возможности и на клиенте. Все
клиентские приложения связываются с серверами DSS с помощью клиентского
компонента, который называется Microsoft PivotTable Service. Эта служба играет
роль "драйвера", управляющего соединением между клиентом и сервером. Значительная
часть кода PivotTable Service совпадает с сервером DSS, так что она приносит
серверный механизм многомерных вычислений, функции кэширования и управления
запросами непосредственно на клиент. В результате мы получаем чрезвычайно
новаторскую клиент-серверную модель управления данными, которая оптимизирует
производительность и сводит к минимуму трафик в сети. Со всем этим связаны
очень небольшие затраты вычислительных ресурсов: для PivotTable Service
необходимо приблизительно 2 Мб дискового пространства, а потребность в памяти
составляет всего 500 Кб в дополнение к кэшируемым данным.