|
||||||||
|
||||||||

|
Новинка SQL Server 2000: индексированные представления
Индексированные представления позволяют заранее провести
разного рода вычисления, агрегирование и все нужные соединения таблиц, так что отпадает
необходимость вводить эти условия в каждый запрос. По данным Microsoft,
производительность приложений, использующих индексированные представления
вместо базовых таблиц, возрастает в десятки и сотни раз. Больше всего выиграют
от применения индексированных представлений приложения, связанные с применением
хранилищ данных, исследованием скрытых зависимостей в данных (Data Mining) и
поддержкой принятия решений. Кэлен Дилани, SQL Magazine OnLine, #04/2000 Мощное средство ускорения обработки запросов и повышения производительности
приложений для системных администраторов.
Звучит слишком хорошо, чтобы быть правдой? Индексированные представления
позволяют заранее провести разного рода вычисления, агрегирование и все нужные
соединения таблиц, так что отпадает необходимость вводить эти условия в каждый
запрос. По данным Microsoft, производительность приложений, использующих
индексированные представления вместо базовых таблиц, возрастает в десятки и
сотни раз. Хотя Oracle поддерживает некий аналог под названием материализованные
представления, разработки Microsoft в области индексированных представлений
оставили далеко позади все предложения конкурентов. (Сравнение реализации
индексированных представлений Microsoft и материализованных представлений
Oracle приводится в приложении "Индексированные представления против
материализованных"). Взгляд с вершины
В SQL Server представления использовались с самого начала. Представление
является, по существу, хранимым оператором SELECT, который играет роль фильтра.
В качестве примера предположим, что у вас имеется большая таблица, содержащая
подробные сведения обо всех клиентах вашей организации. Однако иногда нас
интересуют только фамилии и номера телефонов лиц, проживающих в зоне действия
определенного почтового индекса. В этом случае можно создать представление наподобие следующего: CREATE VIEW local_customers Теперь к нему можно обращаться так, словно это таблица, но, в отличие от
реальной таблицы, при этом не требуется выделять место в памяти. Когда
какой-либо запрос обращается к такому представлению, SQL Server производит
слияние условий, указываемых в запросе, с условиями представления. После этого
SQL Server оптимизирует, компилирует и исполняет полученный в результате такого
слияния запрос. При использовании специальных механизмов кэширования, присущих
SQL Server 7.0, план исполнения этого запроса может быть применен повторно в
будущем, однако более надежную гарантию многократного использования
обеспечивают хранимые процедуры. Представления имеют два основных преимущества. Во-первых, они упрощают
написание запросов, поскольку не только не требуют прямого доступа к таблицам,
но и часто уже включают необходимые ограничения, вычисления, агрегирование и
даже соединение таблиц. Поэтому в запросе можно все эти условия не повторять.
Во-вторых, представления обеспечивают безопасность данных, ведь можно
предоставить пользователям доступ не ко всей таблице в целом, а к
представлениям, в которых содержатся только те данные, которые требуются им для
работы. Представление не сохраняет данные - это, по существу, всего лишь сохраняемый
запрос. Поэтому содержимое представления является динамическим. Если ввести в
таблицу новые строки или изменить уже содержащиеся в ней данные, то
представление покажет обновленную информацию. Однако есть и оборотная сторона
медали. Если представление включает вычисления, использующие сведения из
столбцов таблицы, то, когда кто-то обращается к представлению, SQL Server
производит все вычисления заново. Кроме того, для облегчения обработки запросов
к базе данных нельзя использовать индексы, построенные на столбцах, участвующих
в вычислениях. Рассмотрим типичный случай: представление, показывающее день недели, когда
был принят заказ. В базовой таблице имеется столбец Orderdate, в который
заносятся сведения о дате оформления заказа. Но если желательно показать еще
кое-какие детали заказа, то можно было бы создать следующее представление: USE northwind Это представление можно применить, например, для поиска всех заказов, принятых
в декабре (с целью анализа роста оборота в праздничные дни), однако никакой
индекс не поможет найти нужные строки. Индекс по столбцу Orderdate поможет
отыскать сроки по точной дате, а не по месяцу оформления заказа. С появлением в SQL Server 2000 индексированных представлений стало возможным
построить для этого представления кластеризованный индекс. Кластеризованный
индекс - единственный тип индексов в SQL Server, содержащий данные.
Кластеризованный индекс представления содержит все данные, составляющие
определение представления. Как только вы создадите кластеризованный индекс,
представление материализуется, то есть SQL Server выделит память для его
хранения. После этого можно обращаться с представлением, как с таблицей,
создавая для него множество некластеризованных индексов. (Приводимые в данной
статье объяснения и примеры взяты из программы для первопроходцев SQL Server
2000, Условия для создания представлений
Прежде чем приступать к созданию индексированного представления, необходимо
предусмотреть гарантии того, что представление всегда будет показывать одни и
те же результаты для тех же исходных данных. Для этого убедитесь в том, что в
команде SET соблюдены следующие условия: ARITHABORT Помимо этого следует оператором SET отключить опцию NUMMERIC_ROUNDABORT, то
есть перевести ее в состояние OFF. Инструментарий клиентской части SQL Server 2000 по умолчанию присваивает
правильный статус всем перечисленным опциям за исключением ARITHABORT, что
упрощает работу с индексированными представлениями. Для пущей безопасности
можно воспользоваться процедурой sp_configure, чтобы установить в положение ON
бит, соответствующий ARITHABORT, в user options. Приведенный ниже код
находит user options в таблице syscurconfigs, затем с помощью битовой
арифметики включает соответствующий бит, оставляя без изменений все установки,
которые были сделаны ранее. use master Отметим, что этим опциям должен быть назначен указанный статус при создании
индексированных представлений, при внесении изменений в таблицы, участвующие в
формировании индексированного представления, и в тех случаях, когда оптимизатор
сочтет нужным использовать индексированное представление как часть плана
исполнения запроса. Запустив запрос DBCC USEROPTIONS, можно узнать, какие опции
включены в конкретном случае. Проверить, правильно ли установлена опция, можно
при помощи функции свойств SESSIONPROPERTY (1 соответствует положению ON, а 0 -
положению OFF): SELECT SessionProperty ('NUMERIC_ROUNDABORT') При создании представлений следует помнить, что необходимо выполнить еще ряд
специфических требований. Во-первых, все выражения и функции в определении
представления должны быть детерминированными. В общем случае, любая функция,
которая при двух различных обращениях к ней может вернуть разные результаты для
одних и тех же значений аргументов, не является детерминированной. Легко
привести два примера широко известных недетерминированных функций - это
getdate() и rand(). Большинство системных функций, у которых отсутствуют
параметры, к примеру, @@spid, @@servername и @@rowcount, также не относится к
числу детерминированных функций. Вас может удивить тот факт, что функция
datename() тоже недетерминированная. Дело в том, что ее значения зависят от
того, какой язык был выбран при конфигурировании системы для применения в
процедуре sp_configure. Язык может меняться от пользователя к пользователю при
работе даже на одном сервере, так что один пользователь будет получать
сообщения об ошибках на английском языке, а другой - на испанском. Функция
Datepart() будет недетерминированной, если первым аргументом служит день
недели, DW (day of week), поскольку DW может варьироваться в зависимости от
установки параметра DATEFIRST. В последней версии SQL Server Books Online (BOL)
приведены списки детерминированных и недетерминированных функций. Добавим еще,
что любое представление, в чьем определении содержится ссылка на столбец,
константу или выражение действительного типа с плавающей точкой, не будет
детерминированным. Второе требование, которое необходимо учитывать при создании представления,
состоит в том, что определение схемы любого используемого объекта не должно
меняться. В SQL Server 2000 для предотвращения изменения схемы в операторе
CREATE VIEW предусмотрена опция SCHEMABINDING. Когда эта опция включена,
оператор SELECT в определении представления будет использовать полные имена
(Владелец.Объект) всех таблиц, на которые делаются ссылки. Удалить или изменить
таблицы, участвующие в создании представления с применением оборота
SCHEMABINDING, можно будет только после удаления этого представления или его
изменения таким образом, что опция SCHEMABINDING будет отключена. В противном
случае SQL Server выдаст сообщение об ошибке. Если владельцем таблицы, на которой
вы строите представление, является кто-то другой, то вам не может быть
автоматически предоставлено право создавать определения с использованием
оборота SCHEMABINDING. Ведь иначе права владельца таблицы изменять ее по своему
усмотрению могут быть ущемлены. Владелец таблицы может предоставить другому
пользователю право создавать представление с опцией SCHEMABINDING, выдав ему
разрешение REFERENCES. В SQL Server 2000 на синтаксис, применяемый при создании определений
оператором CREATE VIEW, наложены и другие ограничения. Так, определение
представления не должно содержать:
Кроме того, если определение содержит GROUP BY, то необходимо включить в
список SELECT новый агрегат COUNT_BIG(*). Он возвращает значение в формате
нового типа данных BIGINT, который представляет собой восьмибайтовое целое
число. Представление, содержащее оборот GROUP BY, не может использовать обороты
HAVING, CUBE, ROLLUP и GROUP BY ALL. Все столбцы, указанные в обороте GROUP BY,
обязательно должны быть упомянуты в списке оператора SELECT. Чтобы проверить, все ли перечисленные требования выполнены, используйте
новое значение 'IsIndexable' функции ObjectProperty. Запустив приводимый ниже
запрос, вы узнаете, можно ли построить индекс для представления: SELECT ObjectProperty(object_id('Product_Totals'), 'IsIndexable') Если будет возвращено значение 1, то это означает, что все ограничения
выполнены, и для этого представления можно построить индекс. Хотя перечисленные условия могут показаться суровыми, выигрыш от применения
индексированных представлений перевешивает все трудности подготовительного
этапа. К тому же схожие ограничения накладываются и двумя другими
нововведениями SQL Server 2000, определяемыми пользователями функциями (UDF,
User Defined Function) и индексами для вычисляемых столбцов. Не забывайте, что
упомянутые требования предъявляются только к определениям представлений, а не к
запросам, в которых присутствуют ссылки на индексированные представления. Создание индексированного представления
Теперь, когда вы знаете, что можно и что нельзя включать в индексированное
представление, приступаем к его построению. Сначала следует определить
представление, как это сделано на листинге 1: USE northwind Обратите внимание на оборот SCHEMABINDING и на присутствие в названии таблиц
спецификации их владельца (dbo). На данном этапе имеется обычное представление,
которое не занимает место в памяти. Действительно, если сейчас запустить для
представления процедуру sp_spaceused, то в ответ будет получено сообщение об
ошибке, информирующее о том, что для представлений место в памяти не
выделяется: Server: Msg 15235, Level 16, State 1, Чтобы сделать представление индексированным, необходимо для него создать
уникальный кластеризованный индекс. Следующий оператор создает для
представления Product_Totals уникальный кластеризованный индекс: CREATE UNIQUE CLUSTERED INDEX PV_IDX on После создания индекса можно повторно запустить процедуру sp_spaceused. Данные, образующие индексированное представление, постоянны, причем сами
данные индексированного представления хранятся на уровне листьев
кластеризованного индекса. Нечто подобное для хранения нужной информации можно
создать с помощью временных таблиц. Но временная таблица статична, она не
отражает изменения, вносимые в данные базовых таблиц. В отличие от них SQL
Server автоматически поддерживает индексированные представления, обновляя
хранимую в кластеризованном индексе информацию при каждом изменении данных,
участвующих в формировании представления. После того как будет создан
уникальный кластеризованный индекс, можно для рассматриваемого представления
создать множество некластеризованных индексов. Используя аргумент 'IsIndexed'
функции ObjectProperty, легко определить, является ли индекс кластеризованным.
Для индексированного представления Total_Products следующий оператор возвращает
значение 1, (то есть представление проиндексировано): SELECT ObjectProperty(object_id Заметим, что на стадии тестирования бета-1 при выполнении системной хранимой
процедуры sp_help не формировался отчет о том, является ли представление
индексированным, и не показывались никакие индексы. Однако теперь, запуская для
представления системную хранимую процедуру sp_helpindex, можно получить
исчерпывающую информацию обо всех индексах, существующих для данного
представления. Применение индексированных представлений
Очевидное преимущество использования индексированных представлений состоит в
том, что в запросах больше не надо обращаться напрямую к представлению, чтобы
воспользоваться его индексом. Рассмотрим индексированное представление
Product_Total. Предположим, что вы запустили на выполнение следующий оператор
SELECT: SELECT productid, total_qty = sum(Quantity) Оптимизатор запросов SQL Server учитывает, что заранее вычисленные суммарные
величины числа проданных экземпляров каждого вида товара, Quantity, доступны и
находятся в индексе представления Product_Totals. Поэтому оптимизатор оценит
затраты на применение этого индексированного представления при обработке
рассматриваемого запроса. Тот факт, что индексированное представление
существует, вовсе не означает, что оптимизатор всегда будет его использовать
при составлении плана исполнения запроса. Более того, даже если прямо указать в
обороте FROM индексированное представление, в некоторых случаях оптимизатор
может предпочесть воспользоваться прямым доступом к таблице. Чтобы выяснить, использует ли оптимизатор индексированное представление,
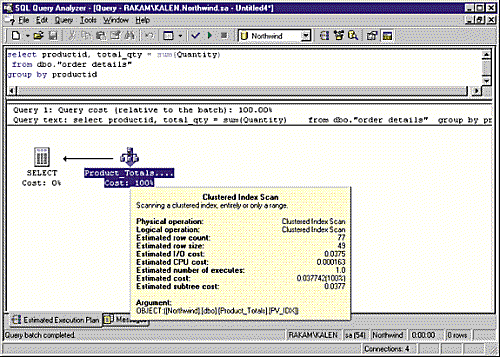
следует посмотреть план выполнения запроса в Query Analyzer. Приведенное на
экране 1 графическое изображение плана исполнения запроса показывает, что в
данном случае оптимизатор воспользовался кластеризованным индексом
представления.
Вы сами сможете сравнить затраты на использование заранее вычисленных
величин, хранящихся в индексированном представлении, с затратами на прямой
доступ к базовой таблице с информацией о заказах. Введенная в SQL Server 2000
новая рекомендация, применяемая в запросе, OPTION (EXPAND VIEWS) заставляет SQL
Server развернуть все индексированные представления в соответствующие операторы
SELECT, так что в этом случае оптимизатор не рассматривает индексы
представлений. Для сравнения затрат на доступ к одним и тем же данным с
применением и без применения индексированных представлений следует включить
сбор статистики командой SET STATISTICS IO ON и запустить код из листинга 2. USE northwind В нем предусмотрено выполнение одного оператора SELECT с использованием
индексированного представления и одного оператора с включенной опцией EXPAND
VIEWS. После этого можно сравнить измеренное в ходе эксперимента число логических
чтений. Автор статьи получила следующие результаты: при использовании
индексированного представления было произведено 2 логических чтения, а без
него, когда SQL Server принудили развернуть представление, их число возросло до
19. Вторая рекомендация, связанная с индексами, NOEXPAND, выполняет функции,
прямо противоположные тем, что реализуются посредством EXPAND VIEWS. Чтобы
заставить SQL Server применить индексированное представление, следует в оборот
FROM включить рекомендацию NOEXPAND, но только в том случае, если в обороте
FROM имеется ссылка на это представление. На листинге 3 приведено
индексированное представление таблицы Orders базы данных Northwind. USE northwind Простой запрос, по которому производится выборка из указанной таблицы, не
использует индекс этого представления, как видно из плана исполнения данного
запроса. Однако применение в запросе рекомендации WITH (NOEXPAND) заставляет
оптимизатор учитывать в плане его исполнения только представление и его
индексы. Оптимизатор не будет принимать во внимание ни саму базовую таблицу, ни
ее индексы. Если же использовать рекомендацию WITH (NOEXPAND) применительно к
представлению, у которого нет индексов, то будет получено следующее сообщение
об ошибке: Server: Msg 8171, Level 16, State 2, Line 1 Процессор базы данных всегда должен развертывать неиндексированные представления
в соответствующие операторы SELECT и осуществлять доступ к данным только через
базовые таблицы. Надо отметить, что в том случае, когда пользователь обращается к таблице в
обороте FROM запроса, рекомендация OPTION (EXPAND VIEWS) не даст SQL Server
задействовать индексированное представление, построенное на этой таблице,
однако в SQL Server 2000 нет рекомендации, позволяющей сделать противоположное.
Невозможно заставить процессор базы данных применить индексированное
представление, если на него нет ссылки в самом запросе. Оптимизатор выясняет,
соответствует ли дерево запроса представления дереву рассматриваемого запроса,
а затем оценивает, что повлечет меньшие затраты: использование индексированного
представления или же обращение к базовой таблице. Более того, оптимизатор SQL
Server 2000 может решить, что использование базовой таблицы настолько
необременительно, что не стоит даже утруждать себя оценкой и сравнением
различных вариантов исполнения запроса, в том числе и с применением
индексированного представления. Как уже отмечалось выше, можно заставить оптимизатор воспользоваться
индексом представления, сделав ссылку на индексированное представление в
обороте FROM и включив в него рекомендацию NOEXPAND. Но нельзя заставить
оптимизатор использовать индекс представления с помощью рекомендации INDEX,
которая советует SQL Server использовать определенный индекс. Если вы
попытаетесь указать INDEX = 1, то вместо того, чтобы использовать
кластеризованный индекс представления, SQL Server обратится к кластеризованному
индексу базовой таблицы. Даже если будет указано имя кластеризованного индекса
представления в рекомендации INDEX, SQL Server будет упрямо обращаться к
кластеризованному индексу базовой таблицы. Если только вы не воспользуетесь
рекомендацией NOEXPAND, SQL Server будет заменять само представление его
определением, так что к тому времени, когда оптимизатор приступит к обработке
запроса, он просто не увидит представления. В ходе тестирования можно отключить использование созданных индексированных
представлений, просто задав в обязательной установке SET неправильное значение.
К примеру, установка ANSI_NULLS OFF отключает использование индексированных
представлений. Смягчение ограничений
Длинный список синтаксических ограничений для оператора CREATE VIEW
относится только к созданию индексированного представления. При выборке из
такого представления можно использовать любые допустимые по правилам SQL
термины. Оптимизатор сам примет решение, включать или нет индексированное
представление в план исполнения запроса. Наиболее существенным неудобством может показаться запрет на включение
агрегирования с подсчетом среднего значения (AVG) в определение представления.
Но вспомните о том, что можно использовать агрегирование с подсчетом суммы,
SUM, и что при наличии других агрегатов необходимо применять агрегат COUNT_BIG.
А это означает, что можно самим подсчитать среднее значение. К примеру, индексированное представление Product_Totals содержит столбцы
total_qty и number для каждого продукта. Для получения среднего значения
достаточно просто разделить первое на второе: SELECT productid, average_qty = total_qty/number План исполнения запроса и собранная статистика STATISTICS IO показывают, что
оптимизатор воспользовался индексированным представлением для обработки данного
запроса. Чтобы убедиться в том, что точно такой же результат будет при агрегировании
среднего значения посредством команды AVG, необходимо запустить следующий
запрос: SELECT productid, average_qty = AVG(Quantity) При выполнении этого второго запроса не только получаются те же самые
результаты, что и в первом случае, но интересно отметить, что оптимизатор и на
этот раз воспользовался индексированным представлением, так что во время
исполнения запроса не тратилось время на вычисление суммы и количества. Однако
от применения индексированных представлений выиграют не все приложения и
запросы. Несколько советов, как отобрать приложения и запросы с целью создания
для них индексированных представлений, приведено в приложении 1 <Отбор
кандидатов для создания индексированных представлений>. Управление индексированными представлениями и их настройка
Во многих отношениях управление индексированными представлениями подобно
управлению обычными представлениями. Процедура sp_help поможет узнать, какие
столбцы вошли в представление, а процедура sp_helptext покажет определение
представления, если только при его создании вы не зашифровали это определение с
помощью опции WITH ENCRYPTION. Оператор DROP VIEW удалит индексированное представление с той же легкостью,
с какой он проделывает это с неиндексированными представлениями. Если вы
удалите кластеризованный индекс представления, SQL Server автоматически удалит
и все некластеризованные егоиндексы. Для внесения изменений в определение
индексированного представления можно воспользоваться командой ALTER VIEW, но
при этом следует знать, что при изменении индексированного представления
исчезнут все индексы этого представления. Чтобы вновь сделать представление
индексированным, необходимо заново построить для него кластеризованный индекс.
В качестве меры предосторожности рекомендуется сохранять все определения
индексов в файлах сценария. В SQL Server 2000 продолжено расширение возможностей мастера создания
индексов, Index Tuning Wizard (ITW), впервые введенного в SQL Server 7.0.
Теперь он не только советует, какие индексы целесообразно построить для
таблицы, но и позволяет строить представления и индексы для них. В версии бета
1 эта опция включена по умолчанию. Но если не нужно, чтобы ITW занимался
индексированными представлениями, ее можно отключить. Если вы все же позволили ITW создавать индексированные представления, будьте
осторожны. Поскольку при создании индексированного представления ITW обеспечивает
ввод правильных значений во все опции команды SET, результаты гипотетического
анализа для представления всегда будут положительными. Однако, если установки
SET в дальнейшем будут изменены и получат другие значения, то приложение не
сможет воспользоваться индексированными представлениями, а выполнение команд
вставки, удаления и обновления таблиц, участвующих в формировании
индексированных представлений, будет завершаться ошибкой. Усиление индексированных представлений
Чтобы извлечь наибольшую пользу из индексированных представлений:
Вносить какие-либо изменения в уже имеющиеся у вас приложения и запросы не
придется. Оптимизатор будет решать, насколько целесообразно применять индексированное
представление, для каждого конкретного случая, а ваши приложения останутся
неизменными. ПРИЛОЖЕНИЕ 1.
Отбор кандидатов для создания индексированных представлений
Выигрыш от использования индексированных представлений SQL Server 2000
смогут получить не все приложения или запросы. Как и в случае обычных индексов,
нельзя получить выгоду от создания бесполезных индексов или тех, что не
применяются в запросах. Создавая неиспользуемые индексы, вы только напрасно
займете дисковое пространство и затратите время на их сопровождение при
изменении базовых таблиц. Однако если ваши приложения и запросы используют
вычисленные заранее результаты, хранящиеся в индексированных представлениях, то
вы получите очень значительный выигрыш в производительности. Больше всего выиграют от применения индексированных представлений
приложения, связанные с применением витрин данных, исследованием скрытых
зависимостей в данных (Data Mining) и поддержкой принятия решений. Для этих
приложений выигрыш будет обусловлен следующим:
В отличие от этих приложений системы, автоматизирующие рутинную обработку
транзакций (OLTP) и выполняющие множество операций записи в случайное множество
строк, не смогут извлечь выгоду из применения индексированных представлений.
Базы данных с превалирующими операциями обновления также не выиграют от
индексированных представлений, поскольку маловероятно, что обновления будут
затрагивать одни и те же строки, входящие в представления. Кроме того, плохими
кандидатами на создание индекса являются представления, полученные просто
пересечением строк и столбцов, для которых не надо ни проводить агрегирование,
ни выполнять заранее какие-либо вычисления. ПРИЛОЖЕНИЕ 2.
Индексированные представления против материализованных
Наверняка многие слышали о том, что корпорация Oracle после выхода в свет
SQL Server 7.0 бросила всем вызов. Формулировку этого вызова меняли три раза,
но последний вариант выглядит так : Корпорация Oracle выплатит 1 миллион долларов тому, кто первым
продемонстрирует, что SQL Server 7.0 с 1-терабайтной базой данных TPC-D может
показать результат, отличающийся от лучших опубликованных результатов Oracle
для запроса номер 5 текущей спецификации TPC-D (версия 1.3.1) менее чем в 100
раз. Соискатель должен выполнить аттестационный 1-терабайтный тест TPC-D
полностью, включая все требуемые операции по загрузке, обновлению данных,
выполнению запросов и публикации полного демаскированного отчета всех метрик
производительности. Соискатель может использовать любые компьютерные платформы,
которые поддерживает SQL Server 7.0. Результаты тестов должны быть опубликованы
сертифицированным аудитором TPС" Позиции Oracle достаточно прочные: корпорация уже ввела материализованные
представления. Совет по оценке производительности транзакций (TPC, Transaction
Processing Performance Council) опубликовал очень подробную документацию со
спецификациями проводимых тестов, и разработчики Oracle смогли создать
материализованные представления специально для запросов, входящих в состав
тестов. Поэтому требовалось только считать с диска заранее вычисленные
результаты, не производя каких-либо расчетов. Если бы в то время в SQL Server
7.0 уже были индексированные представления, корпорация Oracle не рискнула бы
бросить подобный вызов. У индексированных представлений SQL Server 2000 имеется ряд преимуществ по
сравнению с материализованными представлениями Oracle. Во-первых,
материализованные представления не динамичны, то есть после изменения данных
приходится обновлять представления вручную . Во-вторых, оптимизатор запросов
Oracle автоматически не принимает во внимание материализованные представления,
и необходимо явным образом определять их в запросе (в обороте FROM). Независимо от того, какие именно представления вы используете,
индексированные или материализованные, следует заранее знать, какие запросы
будут запускать пользователи. Эти постоянные представления не предназначены для
оптимизации гибких запросов, применяемых при работе с хранилищами данных, что,
по сути, и предполагалось в тесте TPC-D. После того как корпорация Oracle
опубликовала свой вызов, совету TPC пришлось срочно дезавуировать тест TPC-D,
заменив его двумя тестами: TCP-H только для гибких запросов и TCP-R для
запросов с использованием индексированных или материализованных представлений. Кэлен Дилани (kalen_delaney@compuserve.com, http://www.olap.ru/desc/microsoft/www.InsideSQLServer.com)
имеет сертификаты MCT и MCSE, работает независимым консультантом и
преподавателем на северо-западе тихоокеанского побережья США. Начала работать с
SQL Server еще в 1987 году. Кэлен написала книгу "Inside SQL Server
7.0", выпущенную издательством Microsoft Press; она также является
соавтором книг "SQL Server 6.5 Unleashed" и "Teach yourself SQL
Server in 21 days", изданных в Sams Publishing. | ||||||||||
|
За содержание страницы отвечает Гончарова М.Н. © Кафедра СПиКБ, 2002-2017 |
|||||||||||