|
||||||||
|
||||||||

|
Стратегия Microsoft в
области создания хранилищ данных: платформа для совершенствования процессов
принятия решений за счет облегчения доступа и анализа данных Оригинал статьи находится по адресу: http://www.microsoft.ru/msdn/Experts/SQLServer/SQL7_dwa.htm
Введение
Ключевым фактором рыночного успеха в сегодняшних условиях высокой
конкуренции становится оперативное принятие эффективных деловых решений. Однако
естественное стремление многих организаций усовершенствовать свои процессы
принятия решений может натолкнуться на труднопреодолимое препятствие - огромный
объем и высокая сложность данных, содержащихся в разнообразных оперативных и
производственных системах этих организаций. Сделать такую информацию доступной
более широкому кругу бизнес-пользователей - вот одна из наиболее серьезных
проблем, стоящих сегодня перед профессионалами в области информационных
технологий. Многие организации для решения этой задачи избирают путь построения хранилища данных (data warehouse), позволяющего
"высвободить" информацию из жестких рамок оперативных систем и лучше
осознать проблемы реального бизнеса. Хранилище данных - это интегрированный
накопитель информации, собранной из других систем, на основе которого строятся
процессы принятия решений и анализа данных. Несмотря на то что хранилища данных
бывают различных типов и могут опираться на разные методологии, и даже
философии, построения, все они имеют некоторые общие признаки:
Построение хранилищ данных - процесс сложный по самой своей природе и
поэтому обычно дорогостоящий и длительный. В последние несколько лет Microsoft
совместно с другими компаниями отрасли работала над созданием платформы
построения хранилищ данных, включающей в себя как компонентные технологии, так
и передовые продукты и способной снизить затраты и повысить эффективность
создания, администрирования и эксплуатации хранилищ данных. Microsoft также
занималась разработкой инструментов и продуктов - таких как версия 7.0 СУБД
MicrosoftR SQL ServerT - хорошо приспособленных к использованию в процессе
создания хранилищ данных. Эти средства в сочетании с продуктами сторонних фирм,
интегрируемыми на базе инфраструктуры Microsoft Data Warehousing Framework,
предоставляют клиентам широкий выбор способных к совместному функционированию
первоклассных продуктов, которые могут удовлетворить любые их потребности в
построении хранилищ данных. Microsoft SQL Server 7.0 предлагает широчайший набор функций,
предназначенных для поддержки процессов создания хранилищ данных. Сочетая возможности
этой СУБД с архитектурой Data Warehousing Framework, Microsoft предоставляет
платформу, повышающую эффективность и снижающую стоимость и сложность проектов
построения хранилищ данных. Поскольку процесс создания хранилищ данных является итеративным по своей
природе, он требует регулярного перепроектирования в течение всего жизненного
цикла приложения. Процесс создания хранилищ данных
Хранилище данных - это собрание данных, предназначенное для поддержки
принятия управленческих решений и отличающееся предметной ориентированностью, интегрированностью , поддержкой
хронологии и неизменяемостью. Проще говоря, это означает, что
хранилище данных ориентировано на бизнес-понятия (например, продажи), а не на
бизнес-процессы (например, выписку счетов), и содержит всю существенную
информацию, относящуюся к этим понятиям, которая собрана из различных
обрабатывающих систем. Эта информация собирается и представляется за
согласованные периоды времени и не подвержена оперативным изменениям. Хранилище данных интегрирует оперативные данные с помощью согласованных
правил именования, измерений, физических атрибутов и семантики. Первым шагом в построении
хранилища данных является организационный процесс, состоящий в выявлении
предметных областей, которые необходимо отразить в хранилище, и в выработке
некоторого набора согласованных определений. На этом этапе необходимо тесное
общение с конечными пользователями, бизнес-аналитиками и руководством, целью
которого является четкое понимание и документирование круга их информационных
потребностей. Только после того как такое понимание будет достигнуто, возможен
переход от логического к физическому проектированию хранилища данных. Вслед за проектированием физической структуры хранилища необходимо запустить
в работу системы, обеспечивающие его регулярное пополнение данными из
оперативных систем. Поскольку представление данных в оперативных системах и в хранилище
различается, пополнение хранилища данных требует преобразования информации:
агрегирования, трансляции, декодирования, отбраковки ошибочных данных и т.д.
Такие процессы необходимо автоматизировать, чтобы они могли запускаться
регулярно, выполняя извлечение, преобразование и транспортировку исходных
данных настолько часто, насколько это необходимо для удовлетворения
бизнес-требований, предъявляемых к хранилищу данных. В оперативных системах данные являются достоверными и точными на текущий
момент времени - тот, когда происходит обращение к ним. Например, приложение
ввода заказов всегда показывает текущее количество имеющихся на складе
продуктов по каждому их наименованию. Результаты выполнения двух
последовательных запросов о количестве единиц данного продукта могут оказаться
различными, даже если между запросами прошло совсем немного времени. Напротив,
данные в хранилище представляют информацию за длительный период времени и
ожидается, что они будут точными для каждого конкретного момента. Фактически
хранилище содержит длинные последовательности "мгновенных снимков"
текущего состояния ключевых предметных областей бизнеса. В итоге бизнес-аналитики и руководство получают возможность обращаться к
информации для просмотра, анализа и построения отчетов. На этапе анализа можно
применять различные инструменты, от простейших генераторов отчетов до
высокоразвитых средств интеллектуального анализа данных (иначе "добычи
данных", data mining). Результатом выхода на этап анализа, однако,
является вовсе не завершение работы, а запуск очередной итерации в процессе
развития хранилища данных - пересмотра его проекта с целью расширения круга
обрабатываемой информации, повышения производительности системы и включения
новых аналитических задач. С этими модификациями процесс запускается сначала -
и так в течение всего жизненного цикла хранилища данных. Чтобы облегчить работу групп информационных технологий по постоянной
поддержке и развитию хранилищ данных, было предложено множество методологий их
проектирования. Разнообразие решений, в свою очередь, породило бурные дискуссии
относительно того, какая из архитектур разработки корпоративных хранилищ данных
является наилучшей. Архитектуры хранилищ данных
Несмотря на все разнообразие подходов к практической реализации систем поддержки
принятия решений, основных видов хранилищ данных всего два: общекорпоративные хранилища данных (enterprise data
warehouse) и киоски (или витрины) данных (data mart). Оба типа
хранилищ имеют своих сторонников, а также свои сильные и слабые стороны. Корпоративное хранилище данных содержит информацию о всех сторонах
деятельности организации, интегрированную из множества оперативных источников
данных и предназначенную для решения на ее базе задач консолидированного
анализа данных. Обычно оно формируется на основании данных, касающихся
нескольких различных аспектов - например, клиентов, продуктов и продаж - и
служит для поддержки принятия как тактических, так и стратегических решений.
Корпоративное хранилище содержит наряду с детализированными данными, относящимися
к каждому моменту времени, также и агрегированную информацию, а общий объем его
данных варьируется от 50 Гбайт до более чем 1 Тбайт. Корпоративные хранилища
данных могут потребовать больших затрат денег и времени на разработку и
администрирование. Обычно их реализацией занимаются централизованные
ИТ-организации, применяя методологию нисходящего проектирования. Киоски данных содержат некоторое подмножество всех данных корпорации,
которое создается для использования его отдельными подразделениями или отделами
организации. В отличие от корпоративных хранилищ, киоски данных часто строятся
снизу вверх на основе информационных ресурсов подразделения, используемых
конкретным приложением поддержки принятия решений или группой пользователей.
Киоски данных содержат агрегированные, а также часто и детализированные, данные
о предметной области. Хранимая в киоске данных информация может быть
подмножеством корпоративного хранилища (такой киоск называется зависимым), или
же, что встречается чаще, она поступает непосредственно из оперативных
источников данных (независимый киоск данных). Независимо от используемой архитектуры хранилища и киоски данных создаются и
поддерживаются в рамках описанного выше итеративного процесса. Компоненты, используемые при построении хранилищ
данных
Хранилище данных состоит из множества компонентов, среди которых могут быть
следующие:
Microsoft вполне допускает, что некоторые из перечисленных компонентов в
реализации у конкретного клиента могут не быть продуктами Microsoft. На
практике в большинстве случаев хранилища данных строятся именно так - с
использованием самых разнообразных инструментов различных производителей, да
еще в сочетании со специализированным программированием для некоторых задач. Несколько лет назад Microsoft пришла к выводу о существовании насущной
потребности в наборе интегрирующих технологий, которые бы обеспечивали легкость
совместной работы продуктов разных производителей. Такое понимание привело к
созданию концепции Microsoft Data Warehousing Framework (инфраструктура
построения хранилищ данных Microsoft), представляющей собой план развития не
только будущих продуктов Microsoft, таких как SQL Server 7.0, но и технологий,
необходимых для интеграции продуктов множества сторонних производителей,
включая как деловых партнеров Microsoft, так и ее конкурентов. Инфраструктура Microsoft Data Warehousing Framework
Целью создания Data Warehouse Framework является упрощение проектирования,
реализации и администрирования решений в области хранилищ данных за счет
обеспечения таких возможностей как:
Microsoft Data Warehousing Framework предназначена для обеспечения открытой
архитектуры, которую клиенты Microsoft и ее бизнес-партнеры могли бы легко
расширять, опираясь на технологию, имеющую статус промышленного стандарта. Это
позволяет организациям выбирать самые оптимальные компоненты, оставаясь
полностью уверенными в возможности их интеграции. Серьезным аргументом в пользу выбора Microsoft Data Warehousing Framework
клиентами и независимыми поставщиками программного обеспечения является
простота использования. В рамках этой инфраструктуры Microsoft предоставляет
объектно-ориентированный комплект компонентов, обеспечивающих управление
информацией в распределенной среде. Microsoft также предлагает разнообразные
продукты, как начального уровня, так и самые совершенные, которые могут
использоваться на многих шагах процесса построения хранилища данных. Компоненты Data Warehousing
Framework Data Warehousing Framework описывает связи между различными компонентами,
используемыми в процессе создания, использования и администрирования хранилища
данных. Ядром Microsoft Data Warehousing Framework является набор продуктивных
технологий, включающий в себя уровень транспортировки данных (OLE DB) и
интегрированный репозитарий метаданных. Эти две технологии обеспечивают
интегрируемость множества продуктов и инструментальных средств, используемых в
процессе построения хранилища данных. Создание хранилища данных требует применения набора инструментальных средств
для описания логической и физической структуры источников данных и мест их
назначения в хранилищах или киосках данных. Оперативные данные должны пройти
этап очистки и преобразования перед помещением в хранилище или киоск данных,
чтобы соответствовать сформированным на этапе проектирования спецификациям.
Такой процесс поэтапной обработки данных на практике часто бывает
многоуровневым, особенно в архитектурах, использующих общекорпоративные
хранилища, но на приведенной выше схеме он изображен для экономии места в
упрощенном виде. Для обеспечения доступа к информации хранилища данных применяются
инструменты конечных пользователей, в том числе приложения из офисных
комплектов, специализированные аналитические средства и заказные программы. В
идеальном случае, пользовательский доступ осуществляется через некоторое
средство работы с каталогами, предоставляющее возможность поиска именно тех
данных, которые нужны пользователю для решения вопросов бизнеса, а также
обеспечивающее необходимый уровень защиты, лежащий между пользователями и
серверными системами. И наконец, в дело могут включиться самые разнообразные инструменты
управления средой хранилища данных, служащие, например, для планирования
графика выполнения повторяющихся задач и администрирования сетей с несколькими
серверами. Центром интеграции метаданных ("данных о данных"), совместно
используемых разнообразными инструментами, участвующими в процессе построения
хранилища данных, служит репозитарий Microsoft Repository. Эти совместно
используемые метаданные обеспечивают прозрачную интеграцию множества
инструментальных средств различных производителей, устраняя необходимость в
специализированных интерфейсах между каждой парой продуктов. Подробное описание
архитектуры Microsoft Repository приводится в данном документе ниже. Аналогичным образом, интерфейс OLE DB предоставляет стандартизованный,
высокопроизводительный доступ к самым разнородным данным, а также поддерживает
интеграцию данных различных типов. OLE DB подробно описывается в следующем
разделе. Стандарт обмена информацией - OLE DB
Доступ к самым разнообразным потенциальным источникам данных требует
простоты взаимодействия с гетерогенными БД - простого доступа и интегрируемости
- представляя собой одну из наиболее значимых технических проблем, возникающих
в ходе реализации хранилища данных. Data Warehousing Framework опирается на
установленный Microsoft стандарт транспортировки данных - Universal Data Access
- и на интерфейсы OLE DB. Universal Data Access - это концепция, включающая в
себя платформу, приложения и инструменты, в рамках которой не только
определяются стандарты и технологии, но и предлагаются готовые решения. Она
является ключевым элементом предложенной Microsoft базовой архитектуры для
разработки приложений -Microsoft WindowsR Distributed interNet Applications
(DNA). Universal Data Access обеспечивает высокопроизводительный доступ к самым
разнообразным данным и информационным источникам на множестве платформ и
простой интерфейс программирования, который работает практически с любыми
инструментальными средствами и языками, позволяя в максимальной степени
использовать накопленную программистами квалификацию. Технологии,
поддерживающие Universal Data Access, позволяют организациям разрабатывать
простые в эксплуатации решения и пользоваться свободой выбора оптимальных
инструментов, приложений и источников данных на всех уровнях системы -
клиентском, промежуточного звена или серверном. Унифицированная модель доступа к данным на базе COM
Одной из сильных сторон стратегии Microsoft, основанной на стандарте
Universal Data Access, является ее реализация на базе единого набора
современных объектно-ориентированных интерфейсов. Эти интерфейсы опираются на
разработанную Microsoft модель составных объектов Component Object Model (COM),
наиболее широко используемую в мире объектную технологию. Разработчики всего
мира отдают предпочтение COM, поскольку она обеспечивает:
Благодаря обеспечиваемым COM единообразию и интегрируемости предложенная
Microsoft архитектура Universal Data Access (универсальный доступ к данным) является
открытой и работает практически с любыми инструментальными средствами и языками
программирования. Это также позволяет Universal Data Access предоставлять
единую модель доступа к данным на всех уровнях современной архитектуры
приложений. Microsoft Universal Data Access предоставляет интерфейсы на базе COM,
оптимизированные для разработки приложений как на низком, так и на высоком
уровне ( соответственно OLE DB и ADO). Определение OLE DB
OLE DB представляет собой имеющий стратегическое значение для Microsoft
интерфейс программирования на системном уровне, предназначенный для управления
данными в масштабе организации. OLE DB - это открытая спецификация,
разработанная с целью развития успеха ODBC за счет предложения открытого
стандарта для доступа к данным любого типа. Если спецификация ODBC была создана
для доступа к реляционным СУБД, то интерфейс OLE DB нацелен на обеспечение
доступа и к реляционным, и к нереляционным источникам данных, в том числе:
OLE DB определяет набор COM-интерфейсов, инкапсулирующий различные сервисы СУБД.
Эти интерфейсы позволяют создавать программные компоненты, реализующие подобные
сервисы. Среди компонентов OLE DB имеются поставщики данных (хранящие и
предоставляющие данные), потребители данных (использующие данные) и сервисные
компоненты (осуществляющие преобразование и транспортировку данных; такую роль
играют, например, обработчики запросов и механизмы работы с курсорами). Интерфейсы OLE DB предназначены для упрощения "гладкой" интеграции
компонентов, чтобы производители OLE DB-компонентов могли выпускать их на рынок
оперативно и с высоким качеством. Кроме того, в составе OLE DB имеется мост к
ODBC, обеспечивающий продолжение поддержки самых разнообразных разработанных
ранее ODBC-драйверов для реляционных СУБД. Определение ActiveX Data Objects
ActiveXT Data Objects (ADO) - это имеющий стратегическое значение для
Microsoft интерфейс программирования на прикладном уровне для доступа к данным
и информации. ADO обеспечивает единообразный высокопроизводительный доступ к
данным и способен удовлетворять самые разнообразные потребности разработчиков,
в том числе создание клиентских рабочих мест для работы с БД и бизнес-объектов
промежуточного звена с использованием приложений, инструментальных средств,
языков и браузеров Интернета. ADO предназначен для использования в качестве
интерфейса данных при разработке одноуровневых и многоуровневых,
клиент-серверных или веб-решений.
ADO предоставляет простой в использовании интерфейс прикладного уровня к OLE
DB, который осуществляет доступ к данным на более низком уровне. Характерными
особенностями реализации ADO, обеспечивающими "легкость" и высокую
производительность этого интерфейса, являются компактность, минимальный сетевой
трафик в ключевых сценариях и минимальное число уровней между клиентским
рабочим местом и источником данных. ADO прост в освоении, поскольку вызов его
функций осуществляется через интерфейс COM-автоматизации, общепринятой
метафоры, поддерживаемой сегодня всеми распространенными средствами быстрой разработки
приложений, инструментами для работы с СУБД и языками программирования. А
поскольку ADO разрабатывался как интерфейс, сочетающий в себе лучшие
возможности RDO и DAO и призванный в конечном счете заменить их, в нем
используются привычные соглашения с упрощенной семантикой, делающие переход на
него естественным очередным шагом для современных программистов. Метаданные: клей, скрепляющий воедино все хранилище данных
Одной из наиболее трудных задач, возникающих сегодня при реализации хранилищ
данных, является интеграция всех тех разнородных инструментов, которые
используются при его проектировании, преобразовании и накоплении данных и
администрировании. Способность совместного и повторного использования
метаданных - иначе говоря, данных о данных - значительно сокращает сложность и
стоимость создания, эксплуатации и администрирования хранилищ данных. Многие
продукты для построения хранилищ данных предлагают собственные репозитарии
метаданных, которые не могут использоваться прочими компонентами хранилища.
Между тем, каждый инструмент должен иметь возможность легко читать, создавать
или дополнять метаданные, созданные другими инструментами, а также расширять
модель метаданных для конкретных нужд данного инструментального средства. Рассмотрим пример хранилища данных, построенного с применением совместно
используемых метаданных. С помощью инструментов проектирования и преобразования
данных метаданные из оперативных систем помещаются в репозитарий. Подобная
физическая и логическая модель используется продуктами преобразования для
извлечения, контроля корректности и очистки данных перед их загрузкой в БД.
Применяемая СУБД может быть реляционной, многомерной, или сочетать оба этих
подхода. Инструменты доступа к данным и анализа позволяют обращаться к информации
хранилища данных. Информационный каталог интегрирует технические и
аналитические метаданные таким образом, чтобы облегчить поиск и запуск
имеющихся запросов, отчетов и приложений, работающих с хранилищем. В центре инфраструктуры Data Warehouse Framework лежат совместно
используемые метаданные, хранимые в репозитарии Microsoft Repository,
поставляемом в качестве компонента Microsoft SQL Server 7.0. Microsoft
Repository - это БД, хранящая описательную информацию о программных компонентах
и их взаимосвязях. Эта информация включает в себя модели Open Information Model
(OIM) и набор опубликованных COM-интерфейсов. Элементы Open Information Model -
это объектные модели для конкретных типов информации, достаточно гибкие для
того, чтобы поддерживать и новые типы информации, а также быть расширяемыми для
нужд конкретных пользователей или производителей. Microsoft в сотрудничестве с
другими компаниями уже разработала OIM-модели для таких задач как Database
Schema, Data Transformations и OLAP. Планируется подготовка моделей для
тиражирования, планирования графика задач, семантических моделей и
информационного каталога, содержащего метаданные как технического, так и
делового характера. Отраслевой консорциум, в который вошли 53 поставщика, The Metadata
Coalition, созданный для выработки стандартов технологии обмена метаданными
разных производителей, объявил о поддержке Microsoft Repository, а готовые
модели Repository OIM уже широко используются в продуктах сторонних независимых
поставщиков программного обеспечения. Проектирование хранилища данных
Этап разработки, входящий в процесс создания хранилища данных, часто
начинается с построения модели бизнеса с точки зрения измерений, в которой на
основе информационных потребностей пользователей описываются существенные метрики
и измерения избранной предметной области. В отличие от систем оперативной
обработки транзакций (online transaction processing, OLTP), где информация
организована в максимально нормализованном виде, данные в хранилище существенно
денормализуются, чтобы повысить производительность запросов к хранящей их
реляционной СУБД.
Для обеспечения максимально быстрого выполнения сложных запросов в
реляционных БД часто применяются схемы "звезда" и
"снежинка". Схема "звезда" содержит центральную таблицу
фактов предметной области и несколько таблиц измерений, хранящих описательную
информацию об измерениях, характеризующих эти факты. Центральная таблица фактов
может содержать много миллионов строк. Информация, представляющая наибольший
интерес для пользователей, часто проходит предварительное агрегирование и
обобщение, чтобы еще более повысить производительность. Хотя схема "звезда" в первую очередь считается инструментом
администратора БД, повышающим производительность и упрощающим проектирование
хранилища данных, она также представляет собой полезный стандарт представления
информации хранилища данных в виде, хорошо понятном бизнес-пользователям. "Накопитель данных" хранилища
В сердце хранилища данных находится БД, поэтому критически важно строить
подобные системы на базе высокопроизводительного механизма, способного
справиться не только с текущими, но и с будущими потребностями организации.
Реляционные СУБД являются наиболее общепринятыми "резервуарами" для
огромных массивов информации, содержащихся в хранилищах данных. Кроме того, все
чаще и чаще эти реляционные системы дополняются многомерными серверами OLAP,
поддерживающими расширенные средства навигации и повышение производительности
сложных запросов. Также существенными являются средства тиражирования БД в
зависимые киоски данных и обеспечения согласованности между географически разнесенными
зеркальными копиями киосков данных. Масштабируемая и надежная реляционная СУБД
В Microsoft SQL Server 7.0 имеется множество функций, делающих эту СУБД
превосходной платформой для хранилищ и киосков данных, в частности:
Реляционный механизм СУБД Microsoft SQL Server 7.0 применим для хранилищ
данных практически любого размера и сложности. Однако при построении хранилища
данных обычно не ограничиваются только созданием одной центральной БД. На
практике организациям приходится также разворачивать системы поддержки принятия
решений, использующие дополнительные инструменты анализа и распределенные
информационные архитектуры. В составе Microsoft SQL Server 7.0 имеются
серьезные возможности для поддержки и этих задач, лежащих за рамками собственно
управления БД. Интегрированные аналитические средства для OLAP
Online Analytical Processing (оперативная аналитическая обработка, OLAP) -
это набирающая все большую популярность технология, способная значительно
улучшить возможности бизнес-анализа. Исторически сложилось так, что термин OLAP
ассоциировался с дороговизной инструментов, сложностью реализации и отсутствием
гибкости при внедрении. Decision Support Services (сервисы поддержки принятия решений,
DSS) - это новое полнофункциональное OLAP-средство, предоставляемое в качестве
компонента Microsoft SQL Server 7.0. Microsoft DSS имеет в составе сервер
промежуточного звена, позволяющий решать сложнейшие аналитические задачи на
больших объемах данных и получать выдающиеся результаты. Второй компонент
Microsoft DSS - это работающий в клиентской части механизм кэширования и
вычислений PivotTableR Service, позволяющий повысить производительность и
уменьшить сетевой трафик. Кроме того, PivotTable Service предоставляет
пользователям возможность проводить анализ даже тогда, когда они отключены от
корпоративной сети.
OLAP - это ключевой компонент в построении хранилищ данных, и Microsoft DSS
предоставляет мощную функциональность для широкого спектра приложений - от
генерации корпоративных отчетов до высокоразвитых систем поддержки принятия
решений. Включение OLAP-функций в состав SQL Server способно снизить до
разумных пределов стоимость реализации многомерного анализа и открыть
достоинства OLAP более широкому кругу пользователей. Это касается не только
небольших организаций, но также и отдельных пользователей или групп в составе
крупных корпораций, которые ранее были лишены возможности работать с OLAP
вследствие высокой стоимости и сложности соответствующих продуктов. В сочетании с широким выбором инструментов и приложений, поддерживающих
через интерфейс Microsoft OLE DB for OLAP решение прикладных задач на базе
OLAP, Microsoft DSS поможет расширить круг организаций, имеющих доступ к
высокоразвитым инструментам анализа, и снизить затраты на построение хранилищ
данных. Дополнительную информацию о возможностях Microsoft DSS можно почерпнуть в
документе под названием "Microsoft Decision Support Services". Тиражирование
Для создания распределенных зависимых киосков данных на базе центрального
хранилища данных - или даже просто надежного копирования содержимого
независимых киосков данных - необходимо иметь надежные средства тиражирования
(иначе, репликации) информации. Microsoft SQL Server 7.0 содержит в своем
составе средства распространения информации из центрального хранилища данных, выступающего
в роли издателя, во множественные киоски-подписчики. В процессе тиражирования
возможно разбиение информации на разделы - по временным, географическим или
другим ее характеристикам. SQL Server поддерживает разнообразные технологии тиражирования,
приспосабливаемые к нуждам конкретных пользовательских приложений. Каждая из
этих технологий имеет свои преимущества и ограничения, рассматриваемые по трем
важным характеристикам:
Требования, предъявляемые к каждой из этих характеристик отдельно или к их
совокупности, могут варьироваться в различных реализациях распределенных
приложений. В большинстве прикладных систем поддержки принятия решений данные не
модифицируются в отдельных узлах - напротив, информация подготавливается в
неком центральном накопителе, а затем "проталкивается" на
распределенные серверы БД, обеспечивающие удаленный доступ. Именно поэтому для
распространения данных часто применяется метод тиражирования "мгновенных
снимков" (snapshot replication). Как следует из названия этого метода, процедура тиражирования снимков
"фотографирует" состояние подлежащих публикации данных в БД на
текущий момент времени. Вместо того, чтобы повторять в копии выполнение
операторов INSERT, UPDATE и DELETE (так работает транзакционная репликация) или
же отслеживать модификации данных (репликация слиянием), БД-подписчики
(Subscriber) обновляются путем полной замены содержимого наборов данных. Таким
образом, репликация методом "мгновенных снимков" посылает подписчику
все данные, а не только их изменения. Если объем подлежащей пересылке
информации велик, то для ее передачи могут потребоваться серьезные сетевые
ресурсы. Поэтому при решении вопроса о приемлемости тиражирования снимков
необходимо взвесить соотношение между полным объемом набора данных и степенью
их изменчивости. Метод мгновенных снимков - простейший из способов тиражирования,
обеспечивающий согласованность данных у издателя и подписчика. Он также
способствует высокой автономности подписчиков, если последние не модифицируют
данные. Этот тип тиражирования является хорошим решением для подписчиков,
работающих в режиме "только чтение", которым не особенно нужны самые
свежие данные и которые могут полностью отключаться от сети в промежутках между
обновлениями. Тем не менее, SQL Server предоставляет полный диапазон
возможностей тиражирования для самых разнообразных потребностей прикладных
задач. Более подробно о средствах тиражирования в SQL Server 7.0 можно
прочитать в документе под названием "Тиражирование в Microsoft SQL Server
версии 7.0" (SQL Server 7.0 Replication). Импорт-экспорт и преобразование данных
Прежде чем загружать данные в хранилище, их необходимо преобразовать в
некоторый интегрированный, единообразный формат. Такое преобразование
представляет собой последовательность процедурных операций, осуществляемых над
информацией источника данных перед ее загрузкой в запланированное место
назначения. В Microsoft SQL Server 7.0 включено новое средство под названием
Data Transformation Services (сервисы преобразования данных, DTS), которое
поддерживает множество типов преобразований, например, простое отображение
полей, вычисление новых значений по одному или нескольким исходным полям,
декомпозиция содержимого одного исходного поля в несколько целевых полей и
многое другое. Задачи, решаемые Data Transformation Services
Data Transformation Services позволяет решать следующие задачи:
Data Transformation Services позволяет импортировать, экспортировать и
преобразовывать данные из различных источников или в них с помощью архитектуры,
основанной исключительно на OLE DB. OLE DB-источники данных могут быть не
только СУБД-системами, но также и офисными приложениями, например, Microsoft
Excel. Microsoft предоставляет "родные" OLE DB-интерфейсы для СУБД
SQL Server и Oracle. Кроме того, Microsoft разработала OLE DB-оболочку
(wrapper), способную работать с имеющимися ODBC-драйверами для организации
доступа к прочим реляционным источникам. Для текстовых файлов с фиксированными
полями или с разделителями также имеется "родная" поддержка. Архитектура DTS
Определения DTS-преобразований сохраняются в репозитарии Microsoft
Repository, БД SQL Server или в имеющих COM-структуру файлах хранения. Доступ к
оперативным источникам данных - как реляционным, так и нереляционным -
осуществляется через OLE DB. Объект переноса данных (data pump) открывает набор
записей источника и извлекает все записи. Далее объект переноса данных
выполняет функции, записанные на языке сценариев ActiveX Script (VBScript,
JScript или PerlScript), осуществляя копирование, контроль корректности или
преобразование данных между их источником и приемником. Для усложненной
переработки данных возможно создание специализированных
объектов-преобразователей. Новые, преобразованные значения данных, готовые к
помещению в место назначения, возвращаются объекту переноса, который отсылает
их приемнику, пользуясь высокоскоростными операциями передачи данных. Приемники
могут работать через OLE DB или ODBC, быть ASCII-файлами фиксированного формата
или с разделителями или же HTML-файлами.
Сложная логика преобразования и контроля данных может реализовываться с
помощью механизма ActiveX-сценариев. Такие сценарии могут для модификации или
проверки корректности значения поля вызывать методы любого OLE-объекта.
Квалифицированные разработчики могут создавать повторно используемые COM-обекты
преобразования, выполняющие сложные задачи переработки информации. Можно также
выполнять специализированные задачи типа передачи файлов через FTP или запуска
внешних процессов. Независимые поставщики программного обеспечения и консультанты могут
создавать новые источники и приемники данных, разработав для них OLE
DB-интерфейсы. Объект переноса данных способен запрашивать OLE DB-интерфейс,
кем бы он ни был произведен, на предмет наличия поддержки высокоскоростной
загрузки данных и в случае, если таковая не реализована, использовать
стандартные механизмы загрузки. Хотя появление стандартов, подобных ANSI SQL-92, способствовало повышению
интегрируемости механизмов реляционных СУБД, производители в попытках обойти
конкурентов продолжают включать в свои продукты полезные, но, тем не менее,
частные, расширения ANSI SQL. СУБД SQL Server поддерживает несложный язык
программирования, известный под названием Transact-SQL, реализующий базовые
возможности условной обработки и организации циклов. Oracle, Informix и прочие
производители СУБД предлагают сходные, хотя и несовместимые друг с другом,
расширения SQL. Архитектура "сквозного" (pass-through) SQL,
реализованная в механизме преобразования DTS Transformation Engine,
гарантирует, что функциональность источников и приемников будет полностью
доступна пользователям этого механизма. Это позволит пользователям применять
ранее разработанные и отлаженные ими сценарии и хранимые процедуры, просто
запуская их из механизма преобразования. Такая "сквозная" архитектура
значительно упрощает разработку и тестирование, поскольку DTS не модифицирует и
не интерпретирует выполняемые SQL-команды. Любой оператор, который работал при
использовании "родного" интерфейса СУБД, будет работать точно так же
и в процессе преобразования. Data Transformation Services фиксирует и документирует в репозитарии историю
каждого преобразования, так что пользователи получают возможность знать
происхождение своих данных. Происхождение данных может отслеживаться на уровне
как целых таблиц, так и отдельных записей. Это обеспечивает возможность полного
аудита информации хранилища данных. Продукты разных производителей могут
совместно использовать информацию о происхождении данных. Пакеты Data
Transformation Services и сведения о происхождении данных можно хранить
централизованно в Microsoft Repository. В хранимую информацию входят
определения преобразований, VB- и Java-сценарии, а также история выполнения
пакетов. Интеграция с репозитарием предоставляет сторонним фирмам возможность
опираться на инфраструктуру, обеспечиваемую механизмом Transformation Engine.
Запуск DTS-пакетов может планироваться на определенные моменты времени с
помощью интегрированного календаря, выполняться в интерактивном режиме или в
качестве реакции на системные события. DTS-пакеты Пакет Data Transformation Services представляет собой полное описание всех
действий, которые должны быть выполнены в ходе преобразования. Каждый пакет
определяет одну или несколько задач, выполняемых в некой координированной
последовательности. DTS-пакет можно создавать интерактивно с помощью любого
графического интерфейса пользователя или же на любом языке, поддерживающем
OLE-автоматизацию. DTS-пакет можно сохранять в репозитарии Microsoft
Repository, в БД SQL Server или в виде COM-структурированного файла хранения.
При считывании пакета из репозитария или структурированного файла хранения он
выполняется точно так же, как DTS-пакет, созданный интерактивно.
Задача представляет собой определение некоторой порции работы, которую
необходимо выполнить в ходе преобразования, а DTS-пакет составляется из одной
или нескольких задач. Задача может реализовывать транспортировку и
преобразование разнородных данных из OLE DB-источника в OLE DB-приемник с
помощью объекта переноса данных DTS Data Pump, выполнять сценарий ActiveX Sript
или же запускать внешнюю программу. Затем задачи выполняются объектами-шагами. Объекты-шаги координируют потоки управления и выполнения задач в DTS-пакете.
Некоторые задачи должны выполняться в определенном порядке. Например, сначала
следует создать БД (Задача А) и лишь затем можно создавать таблицу в ней
(Задача Б). Этот пример иллюстрирует связь типа "завершение-запуск"
между Задачей А и Задачей Б; таким образом, Задача Б имеет ограничение по
предшествованию, связанное с Задачей А. Каждая задача запускается только тогда,
когда все ее ограничения по предшествованию будут сняты. Возможен условный
запуск задач в зависимости от выполнения некоторых условий на этапе исполнения.
Несколько задач могут быть запущены параллельно, что повышает
производительность процесса. Например, пакет может одновременно загружать
данные в две разные таблицы из СУБД Oracle и DB2. Кроме того, объекты-шаги
управляют приоритетами задач. Приоритет шага определяет приоритет Win32-потока,
реализующего задачу. Объект переноса данных DTS Data Pump является объектом OLE DB Service
Provider, предоставляющим инфраструктуру для импорта, экспорта и преобразования
данных между гетерогенными накопителями данных. OLE DB - это стратегический для
Microsoft интерфейс доступа к данным, обеспечивающий доступ к максимально широкому
диапазону реляционных и нереляционных накопителей данных. DTS Data Pump
представляет собой высокоскоростной внутренний COM-сервер, осуществляющий
транспортировку и преобразование наборов записей, поддерживающих интерфейс OLE
DB. Преобразование - это набор процедурных операций, которые должны быть
применены к записям источника, прежде чем они смогут быть сохранены в нужном
месте назначения. DTS Data Pump поддерживает расширяемую, основанную на COM
архитектуру, позволяющую реализовывать сложные процедуры контроля корректности
и преобразования данных в ходе их перемещения от источника к приемнику. Data
Pump позволяет полностью использовать в DTS-пакетах всю мощь языков сценариев
ActiveX. Это дает возможность выражать сложную процедурную логику в виде несложных,
повторно используемых ActiveX-сценариев. Последние могут осуществлять контроль
корректности, конверсию или преобразование данных в процессе их движения от
источника через объект переноса Data Pump к приемнику. Можно легко реализовать
вычисление новых значений по значениям одного или нескольких полей исходного
набора записей. Возможно и разделение содержимого одного исходного поля на
несколько полей-приемников. ActiveX-сценарии также могут вызывать и
использовать сервисы любого COM-объекта, поддерживающего механизм
автоматизации. Создание DTS-пакетов
DTS-пакеты можно создавать с помощью мастеров импорта-экспорта, инструмента
DTS Package Designer или программным способом. Мастера импорта-экспорта
предлагают самый простой механизм транспортировки данных в хранилище и из него,
однако сложность преобразования в этом случае ограничена заложенными в эти
программы возможностями. Мастер, например, поддерживает работу только с одним
источником и одном приемником данных. Для реализации же возможностей DTS в полном
объеме можно воспользоваться инструментом DTS Package Designer, предоставляющим
простой в использовании и наглядный интерфейс. В рамках этого средства
пользователи могут определять отношения предшествования, сложные запросы,
потоки управления и доступ к множественным гетерогенным источникам данных.
Рис. 6. Инструмент DTS Package Designer предоставляет графическую среду для
описания потоков данных и алгоритмов выполнения пакета. Анализ и представление данных
Microsoft предоставляет множество механизмов формирования запросов
информации, содержащейся в хранилище данных. Например, продукты Microsoft
Access и Microsoft Excel, входящие в состав комплекта инструментальных средств
повышения производительности труда пользователей Microsoft Office, содержат
средства выполнения запросов и анализа информации хранилища данных. В состав
СУБД SQL Server 7.0 включен компонент, называемый English Query, который
позволяет пользователям формировать запросы к БД в виде несложных предложений
на естественном (английском) языке. Кроме того, для решения более сложных задач
визуализации и анализа данных имеется множество продуктов, совместимых с
технологиями Microsoft через инфраструктуру Data Warehousing Framework. Комплект Microsoft Office
Двумя наиболее общеупотребительными инструментами доступа и манипулирования
данными для поддержки принятия решений являются Microsoft Access и Microsoft
Excel. С выходом следующей версии комплекта Microsoft Office, которая будет называться
Microsoft Office 2000, у пользователей появится еще больше возможностей для
анализа и представления информации, содержащейся в их хранилищах данных.
Возможности Microsoft Excel будут расширены поддержкой табличного и
графического представлений для OLAP-источников данных через интерфейсы OLE DB
for OLAP. Одновременно имеющаяся функция PivotTableT будет заменена на более
развитое OLAP-средство, основанное на компоненте Microsoft DSS - PivotTable
Service. В Microsoft Access к имеющимся средствам доступа к БД Access будет
добавлена прозрачная поддержка для работы с БД под управлением SQL Server. Эти
новые возможности позволят пользователям применять привычные офисные
инструменты для гораздо более глубокого анализа данных. В Microsoft Office 2000 будет также включено множество компонентов,
помогающих упростить создание веб-приложений на базе готовых элементов
управления. Эти элементы будут поддерживать доступ к реляционным и OLAP-БД,
позволяя расширить круг пользователей, имеющих возможность просмотра информации
хранилища данных. English Query
English Query - это инструмент в составе Microsoft SQL Server 7.0, с помощью
которого можно строить приложения для работы с хранилищем данных, которые
позволяют извлекать информацию из БД под управлением SQL Server, применяя не
формальный язык запросов типа SQL, а естественный английский. Например, можно
спросить: "How many widgets were sold in Washington last year?" ("Сколько
товаров было продано в прошлом году в Вашингтоне?"), вместо того, чтобы
писать SQL-операторы: SELECT sum(Orders.Quantity) from Orders, PartsWHERE Orders.State='WA'and Datepart(Orders.Purchase_Date,'Year')='1996'and Parts.PartName='widget'and Orders.Part_ID=Parts.Part_ID Приложение, использующее English Query, принимает команды, операторы и
вопросы на английском языке и определяет их смысл. Затем оно формирует
SQL-запрос к СУБД, выполняет его и форматирует полученный ответ. Если исходный
вопрос не удается интерпретировать, English Query может запросить у
пользователя дополнительную информацию. В English Query заложены обширные
сведения по синтаксису и практике использования языка, однако разработчику
приложения нужно создать домен с информацией о тех данных, которые должны стать
доступными пользователю. В контексте Microsoft English Query домен - это
собрание всей информации, известной относительно объектов в приложении,
созданном на основе English Query. Эта информация включает заданные объекты БД
(например, таблицы, поля и соединения), семантические объекты (например,
сущности, связи между ними и дополнительные элементы словаря), а также
глобальные режимы умолчания для всего домена. Первым шагом построения English Query-приложения является моделирование
семантики хранилища данных. Разработчик отображает сущности английского языка
(имена существительные) и отношения между ними (глаголы, прилагательные,
свойства и подмножества) на таблицы, поля и соединения в БД. Это делается с
помощью инструмента создания веб-страниц, позволяющего тестировать домен вне
рамок приложения.
Как только для домена будет построена модель, достаточная для поддержки
пользовательского доступа к данным и тестирования, разработчик активизирует
English Query-приложение через приложение на Visual Basic или через
веб-реализацию на базе Active Server Pages. С ростом популярности средств
доступа к информации хранилищ данных через интрасети English Query становится
великолепным инструментом подключения пользователей к информационным ресурсам
без специального обучения и применения дорогостоящих инструментов поддержки
запросов. На этапе исполнения конечный пользователь English Query-приложения
обращается к веб-странице с помощью Microsoft Internet Explorer (или другого
средства просмотра ресурсов Интернета) и вводит свой вопрос. Microsoft Internet
Explorer передает на Intenet Information Server (IIS) текст вопроса вместе с
адресом страницы Active Server Page (ASP), выполняющей написанный на VBScript
сценарий. Этот сценарий передает текст вопроса English Query для его трансляции в
SQL-команду. English Query использует заданные в домене знания о целевой БД (в
форме English Query-приложения) для разбора текста вопроса и его трансляции в
SQL. Сценарий получает сформированный текст на SQL, выполняет его (с помощью
элемента управления ASP для работы с БД), форматирует результат на языке HTML и
возвращает страницу с ответом пользователю. В комплект поставки English Query включены примеры ASP-страниц, которые
можно использовать в исходном виде, например, для быстрого создания прототипов
или же настраивать, чтобы обеспечить единый стиль оформления с уже имеющимися
веб-приложениями. Продукты сторонних производителей
Фундаментальным свойством инфраструктуры Microsoft Data Warehousing Framework
является открытость этого решения для компонентов сторонних производителей.
Через ODBC и OLE DB, стандарты интерфейса СУБД, десятки продуктов получают
возможность доступа к информации, хранящейся в SQL Server или других
реляционных БД, и манипулирования ею. Аналогичным образом, интерфейс для
многомерных БД OLE DB for OLAP делает доступной информацию из Microsoft
Decision Support Services или из других OLAP-накопителей данных. Благодаря этим
двум стандартам доступа организации получают возможность выбора наиболее
подходящих для их потребностей аналитических инструментов. Сокращение расходов
производителей программного обеспечения за счет стандартизации обещает также
постоянное снижение затрат пользователей на приобретение лучших в своих классах
продуктов. Системное администрирование
Одним из наиболее существенных скрытых источников затрат при реализации
хранилищ данных является постоянное сопровождение и администрирование этих
систем. Существующие технологии обычно требуют от персонала специальных навыков
в управлении реляционными БД и OLAP-серверами и в технологиях проектирования и
преобразования данных. Это означает, что для решения глобальных, связанных друг
с другом задач необходимо привлекать несколько специально подготовленных в
различных областях сотрудников. Предлагаемая же инфраструктура Microsoft Data
Warehousing Framework обеспечивает интегрированный уровень управления и
администрирования, который могут использовать совместно все компоненты,
задействованные в процессе создания хранилища данных. Microsoft предлагает
встроенное средство управления Microsoft Management Console для линий продуктов
Microsoft, которое упрощает переключение между задачами и даже между различными
продуктами. Это средство может расширяться пользователями, консультантами и
независимыми производителями программного обеспечения, желающими настраивать
высокоспециализированные интерфейсы для конкретных сред. Приложения,
расширяющие возможности данного управляющего средства, поставляются в виде
подключаемых программ (snap-in) и могут представлять собой либо сформированные
в пакеты пользовательские интерфейсы, подготовленные производителем
программного обеспечения, либо специализированные интерфейсы, разработанные
независимо друг от друга, но имеющие доступ к функциям продуктов более низкого
уровня, например, SQL Server. Как и большинство других компонентов комплекта
Microsoft BackOfficeR, SQL Server 7.0 поставляется как подключаемая программа
для Microsoft Management Console. Встроенное средство управления Microsoft Management
Console
Microsoft Management Console (MMC) предоставляет единообразный, хорошо
знакомый пользователям интерфейс для доступа к функциям серверных продуктов
Microsoft. Пользовательский интерфейс MMC похож на среду Windows Explorer,
аналогично ей предлагая разделенную по вертикали рабочую область с деревьями
категорий и объектов, относящихся к определенному серверу, в левой части экрана
с дополнительной подробной информацией о выбранном элементе в правой части.
Детализированная информация правой панели может отображаться самыми различными
способами, в том числе в виде HTML-документа. Новое управляющее средство
позволяет применять более совершенные инструменты, помогающие в работе
начинающим пользователям или недостаточно опытным администраторам БД. Одним из
существенных добавлений являются панели задач, группирующие вместе инструменты
для выполнения таких многоаспектных действий, как создание БД, установка
параметров защиты пользователей и мониторинг БД под управлением SQL Server.
Панели задач содержат также справочную информацию, средства для выполнения
действий под управлением системы и ссылки на разнообразные программы-мастера,
описываемые ниже. Мастера
Microsoft SQL Server 7.0 содержит более 25 мастеров, помогающих легче
справляться с часто выполняемыми задачами, такими как:
Применение мастеров значительно сокращает время обучения администраторов
СУБД, необходимое для освоения навыков продуктивной работы с Microsoft SQL
Server. В среде с хранилищами данных, когда администраторам БД зачастую
приходится поддерживать множество разных действий, реализуемых различными
продуктами, пользование мастерами помогает экономить и время, и деньги. Средство Visual Database Diagrams
Поскольку приложения, работающие с хранилищами данных, отличаются большей
итеративностью, нежели OLTP-системы, используемые первыми структуры и схемы БД
имеют тенденцию меняться чаще. Средство Visual Database Diagrams предоставляет
администраторам БД под управлением Microsoft SQL Server инструменты
моделирования физических структур данных, упрощающие планирование и реализацию
циклов пересмотра системы. Диаграммы сохраняются на сервере СУБД с помощью
средства SQL Server 7.0 Enterprise Manager. Изменения, внесенные в БД,
отображаются в ее диаграмме, и наоборот. Имеется мастер для автоматизации
выбора и размещения на диаграмме таблиц существующей БД. Тем не менее, сущности
БД (таблицы и их связи) можно определять и без его помощи, только средствами
инструмента Diagram.
Инструмент мониторинга событий СУБД SQL Server
Profiler
Для осуществления надлежащей тонкой настройки параметров реляционных БД
необходимо постоянно иметь информацию о статистике ее реального использования.
SQL Server Profiler - это графический инструмент, позволяющий системным
администраторам осуществлять мониторинг событий, обрабатываемых механизмом
Microsoft SQL Server, путем постоянной регистрации в реальном масштабе времени
всех действий сервера. SQL Server Profiler отслеживает происходящие в SQL
Server события, фильтрует их на базе задаваемых пользователем критериев и
направляет трассировочную информацию на экран, в файл или в таблицу БД. На
основе этих данных SQL Server Profiler предоставляет администраторам БД
возможность повторного "проигрывания" зарегистрированных
последовательностей действий для тестирования изменений структур БД,
идентификации неэффективно выполняемых запросов, разрешения проблемных ситуаций
или восстановления состояния БД на предыдущие моменты времени. Приведем примеры отрабатываемых механизмом СУБД событий, которые можно
отслеживать:
Данные о каждом событии могут регистрироваться и сохраняться для
последующего анализа в файле или в таблице SQL Server. Данные о событиях в СУБД
собираются путем создания трассировок, которые могут содержать информацию о
SQL-операторах и результатах их выполнения, о том, какой пользователь и с
какого компьютера запускал эти операторы, и о времени начала и завершения
каждого события. Данные о событиях можно фильтровать так, чтобы их сбор осуществлялся только
по некоторому подмножеству событий. Это позволяет администратору БД ограничить
сбор только интересующими его событиями. Например, можно собирать только
события, затрагивающие определенную БД, или инициируемые конкретным
пользователем, игнорируя все прочие. Аналогичным образом можно задать сбор
данных только о тех запросах, время выполнения которых превышает заданное
значение. SQL Server Profiler оснащен графическим интерфейсом для работы с набором
расширенных хранимых процедур, которые пользователи могут непосредственно
применять. Таким образом, на основе расширенных хранимых процедур SQL Server
Profiler можно создавать собственные приложения для мониторинга SQL Server. Анализатор запросов SQL Server Query Analyzer
SQL Server Query Analyzer - это великолепный инструмент для интерактивного
оперативного выполнения любых операторов и сценариев, написанных на
Transact-SQL (языке запросов SQL Server). Поскольку для использования SQL
Server Query Analyzer необходимо владеть Transact-SQL, этот инструмент
предназначен в основном для квалифицированных пользователей и администраторов
БД. Пользователи вводят операторы Transact-SQL в полнотекстовом окне, выполняют
их и просматривают результаты в текстовом окне или в табличном виде. Аналогично
можно запустить и просмотреть результаты выполнения операторов Transact-SQL,
записанных в текстовом файле. SQL Server Query Analyzer предоставляет также отличные инструменты для
анализа механизмов интерпретации и обработки СУБД Microsoft SQL Server
операторов Transact-SQL. Пользователь может делать следующее:
Мастер настройки индексов Index Tuning Wizard
Одним из наиболее трудоемких и плохо формализуемых процессов в
администрировании реляционных БД является создание индексов, оптимизирующих
производительность выполнения пользовательских запросов. Совместная работа
исследовательского подразделения Microsoft Research и команды разработчиков SQL
Server привела к появлению инструмента, способного облегчить решение этой
задачи. Мастер настройки индексов Index Tuning Wizard - это новый инструмент,
позволяющий администраторам СУБД SQL Server легко создавать и реализовывать
индексы без предварительного глубокого изучения ими структуры БД, аппаратных
платформ и компонентов, а также деталей взаимодействия приложений конечных
пользователей с реляционным механизмом. Index Tuning Wizard самостоятельно
анализирует реальное функционирование БД под управлением SQL Server и
рекомендует для них оптимальную конфигурацию индексов. SQL Server Tuning Wizard может решать следующие задачи:
С помощью Index Tuning Wizard можно анализировать SQL-сценарии или данные
трассировки, подготовленные SQL Server Profiler, и вырабатывать рекомендации на
основе данных об эффективности работы имеющихся индексов, на которые есть
ссылки в сценарии или трассировочном файле. Рекомендации формируются в виде
набора SQL-операторов, реализующих удаление старых индексов и создание новых,
более эффективных. Предложенные мастером рекомендации можно сохранить в виде
SQL-сценария, чтобы пользователь смог позже запустить его вручную,
запланировать на определенное время, сформировав задание SQL Server на запуск
этого SQL-сценария, или же просто немедленно выполнить. Если готовых к анализу с помощью Index Tuning Wizard исходных данных -
SQL-сценариев или трассировок - не имеется, мастер может формировать таковые
сразу или запланировать их создание на какое-то другое время, обратившись к SQL
Server Profiler. Как только администратор БД примет решение о том, что
собранная трассировка действительно является представительной выборкой для
задач, реально выполняющихся в анализируемой БД, мастер сможет исследовать
зарегистрированные данные и рекомендовать конфигурацию индексов, способную
улучшить производительность БД. Автоматизированное администрирование
Администраторы хранилищ данных могут серьезно выиграть за счет автоматизации
рутинных задач - например, резервного копирования БД. Автоматизация
административных задач в SQL Server выполняется следующим образом: сначала
определяются задачи, которые должны выполняться регулярно и могут управляться
программно, а затем формируется набор заданий и предупреждений для сервиса SQL
Server Agent. Автоматизированное администрирование возможно как в среде с одним
сервером, так и в многосерверных конфигурациях. Ключевыми компонентами автоматизированного администрирования являются
задания, пользователи-операторы и предупреждения. Задание - это единожды
сформированное определение административной задачи, которое может выполняться
многократно и контролироваться на предмет успешного или неуспешного завершения
при каждом запуске. Возможны разнообразные схемы организации заданий: их можно
запускать на одном локальном сервере или на нескольких удаленных серверах; в
соответствии с одним или несколькими графиками; при выдаче одного или
нескольких предупреждений; наконец, задания могут состоять из одного или многих
шагов. Шаг задания может представлять собой исполняемую программу, команду
Windows NT, оператор Transact-SQL, сценарий ActiveScript или вызов агента
тиражирования. Пользователь-оператор - это лицо, ответственное за сопровождение одного или
нескольких серверов, где работает СУБД SQL Server. В некоторых организациях все
операторские обязанности возлагаются на одного человека. В более крупных
организациях с многими серверами обязанности оператора обычно распределяются
между несколькими сотрудниками. Операторы извещаются о состоянии вверенных им
систем через электронную почту, пейджинговую связь или сетевой обмен
сообщениями. Предупреждение представляет собой определение, в котором задается реакция на
наступление определенного события или группы событий SQL Server. В общем случае
администратор не имеет возможности управлять возникновением событий, но он
может управлять реакциями на них - через механизм предупреждений. Реакцией на
событие SQL Server, задаваемой в предупреждении, может быть извещение одного или
нескольких операторов, пересылка события другому серверу или возбуждение
исключительной ситуации, воспринимаемой другими программными инструментами. Комбинируя извещения и действия (можно автоматизировать с помощью сервиса
SQL Server Agent), администраторы могут строить высоконадежную самоуправляемую
среду для большей части своих повседневных эксплуатационных задач. Это
высвобождает администраторам больше времени для более серьезных задач,
требующих их персонального внимания. Заключение
Разработав технологии, лежащие в основе инфраструктуры Microsoft Data
Warehousing Framework, и внеся значительные усовершенствования в новую версию
7.0 СУБД Microsoft SQL Server, Microsoft продолжает работать над снижением
сложности, повышением интеграции и уменьшением расходов при построении хранилищ
данных. Клиенты, инвестирующие средства в технологию хранилищ данных на базе
платформы Microsoft, могут быть уверены - они создают приложения на самых
выгодных экономически условиях, обеспечивая одновременно полную масштабируемость
и надежность своих систем. Информация,
содержащаяся в этом документе, представляет текущую точку зрения корпорации
Microsoft на обсуждаемые вопросы на момент публикации. Поскольку Microsoft
должна реагировать на изменяющиеся условия на рынке, документ не следует
рассматривать как обязательство со стороны Microsoft; корпорация Microsoft не
может гарантировать, что вся представленная информация сохранит точность после
даты публикации. Настоящий документ
предназначен только для информационных целей. MICROSOFT НЕ ДАЕТ В ЭТОМ
ДОКУМЕНТЕ НИКАКИХ ЯВНЫХ ИЛИ ПОДРАЗУМЕВАЕМЫХ ГАРАНТИЙ. c1998 Microsoft Corporation. Все права защищены. Microsoft, ActiveX, BackOffice, логотип BackOffice, FrontPage, Visual Basic, Visual C++,
Visual J++, Win32, Windows, Windows NT и Visual Studio 97 представляют собой товарные знаки или зарегистрированные товарные знаки корпорации Microsoft в США и других странах. Прочие упоминаемые
здесь товарные знаки и товарные имена являются собственностью соответствующих
владельцев. Имена или названия
компаний, продуктов, людей, персонажей и/или данных, упоминаемые в этом
документе, являются фиктивными и никоим образом не должны ассоциироваться с
реальными лицами, компаниями, продуктами или событиями, если обратное не
указано явно. Microsoft Part Number:
098-80704 | ||||||||||
|
За содержание страницы отвечает Гончарова М.Н. © Кафедра СПиКБ, 2002-2017 |
|||||||||||

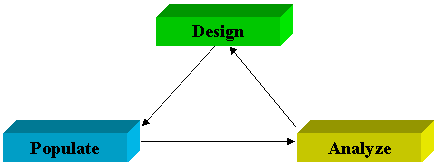 С точки зрения
информационных технологий построение хранилищ данных имеет целью обеспечить
своевременное предоставление нужной информации именно тем сотрудникам
организации, кому это необходимо. Этот вопрос невозможно решить один раз и
навсегда, к нему нужно возвращаться постоянно, поэтому здесь требуется подход,
отличный от применяемого при проектировании транзакционных систем.
С точки зрения
информационных технологий построение хранилищ данных имеет целью обеспечить
своевременное предоставление нужной информации именно тем сотрудникам
организации, кому это необходимо. Этот вопрос невозможно решить один раз и
навсегда, к нему нужно возвращаться постоянно, поэтому здесь требуется подход,
отличный от применяемого при проектировании транзакционных систем.  Архитектура Microsoft
Data Warehousing Framework представляет собой план разработки и интеграции продуктов,
базирующихся на платформе Microsoft
Архитектура Microsoft
Data Warehousing Framework представляет собой план разработки и интеграции продуктов,
базирующихся на платформе Microsoft 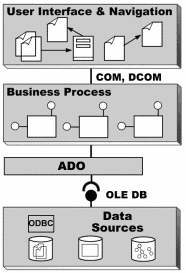 Рис. 1. Архитектура
Universal Data Access
Рис. 1. Архитектура
Universal Data Access 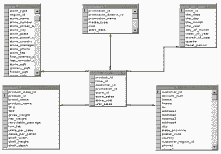 Рис. 2. Пример схемы
"звезда". В рамках этой схемы БД центральная таблица
"фактов" снабжается ссылками на связанные с ней справочные таблицы,
иначе называемые таблицами измерений.
Рис. 2. Пример схемы
"звезда". В рамках этой схемы БД центральная таблица
"фактов" снабжается ссылками на связанные с ней справочные таблицы,
иначе называемые таблицами измерений. 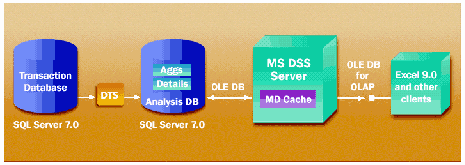 Рис. 3. Microsoft DSS -
OLAP-сервер промежуточного звена, упрощающий пользователям навигацию по данным
и повышающий производительность запросов к информации хранилища данных.
Рис. 3. Microsoft DSS -
OLAP-сервер промежуточного звена, упрощающий пользователям навигацию по данным
и повышающий производительность запросов к информации хранилища данных. 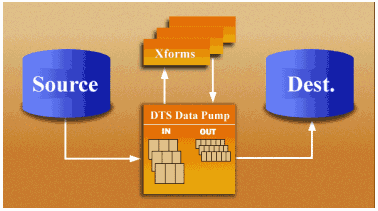 Рис. 4. Архитектура DTS.
Данные извлекаются из систем-источников с помощью основанного на OLE DB объекта
переноса данных и могут при необходимости быть преобразованы перед посылкой в
OLE DB-приемники.
Рис. 4. Архитектура DTS.
Данные извлекаются из систем-источников с помощью основанного на OLE DB объекта
переноса данных и могут при необходимости быть преобразованы перед посылкой в
OLE DB-приемники.  Рис. 5. DTS-пакеты могут
содержать одну или несколько задач любой сложности - от простого отображения
одной таблицы в другую до запуска внешнего процесса очистки данных.
Рис. 5. DTS-пакеты могут
содержать одну или несколько задач любой сложности - от простого отображения
одной таблицы в другую до запуска внешнего процесса очистки данных. 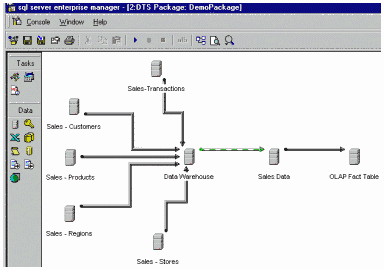 Наконец, DTS-пакеты могут
определяться и запускаться из приложений, реализующих программирование через
COM-интерфейс. Такой способ обычно применяют независимые поставщики
программного обеспечения, желающие использовать возможности DTS для того, чтобы
избавить пользователей от необходимости определять пакеты.
Наконец, DTS-пакеты могут
определяться и запускаться из приложений, реализующих программирование через
COM-интерфейс. Такой способ обычно применяют независимые поставщики
программного обеспечения, желающие использовать возможности DTS для того, чтобы
избавить пользователей от необходимости определять пакеты. 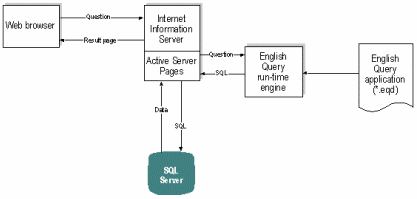 Рис. 7. Потоки информации
между созданным на основе English Query веб-приложением и СУБД SQL
Server.
Рис. 7. Потоки информации
между созданным на основе English Query веб-приложением и СУБД SQL
Server. 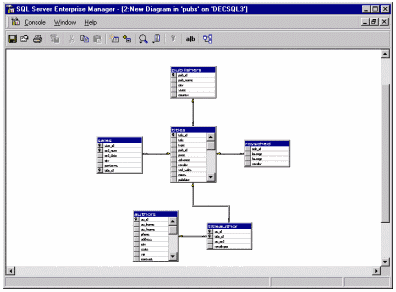 Рис. 8. Инструмент
Database Diagram показывает таблицы и их связи, а также позволяет менять
структуру отдельных таблиц и ограничений, связывающих таблицы. При сохранении
диаграммы внесенные в нее изменения выполняются и в самой БД.
Рис. 8. Инструмент
Database Diagram показывает таблицы и их связи, а также позволяет менять
структуру отдельных таблиц и ограничений, связывающих таблицы. При сохранении
диаграммы внесенные в нее изменения выполняются и в самой БД.  Рис. 9. Инструмент SQL
Server 7.0 Query Analyzer показывает в графическом виде алгоритмы обработки
сложных запросов. В данном примере отдельные части запроса распараллеливаются
для повышения производительности.
Рис. 9. Инструмент SQL
Server 7.0 Query Analyzer показывает в графическом виде алгоритмы обработки
сложных запросов. В данном примере отдельные части запроса распараллеливаются
для повышения производительности.